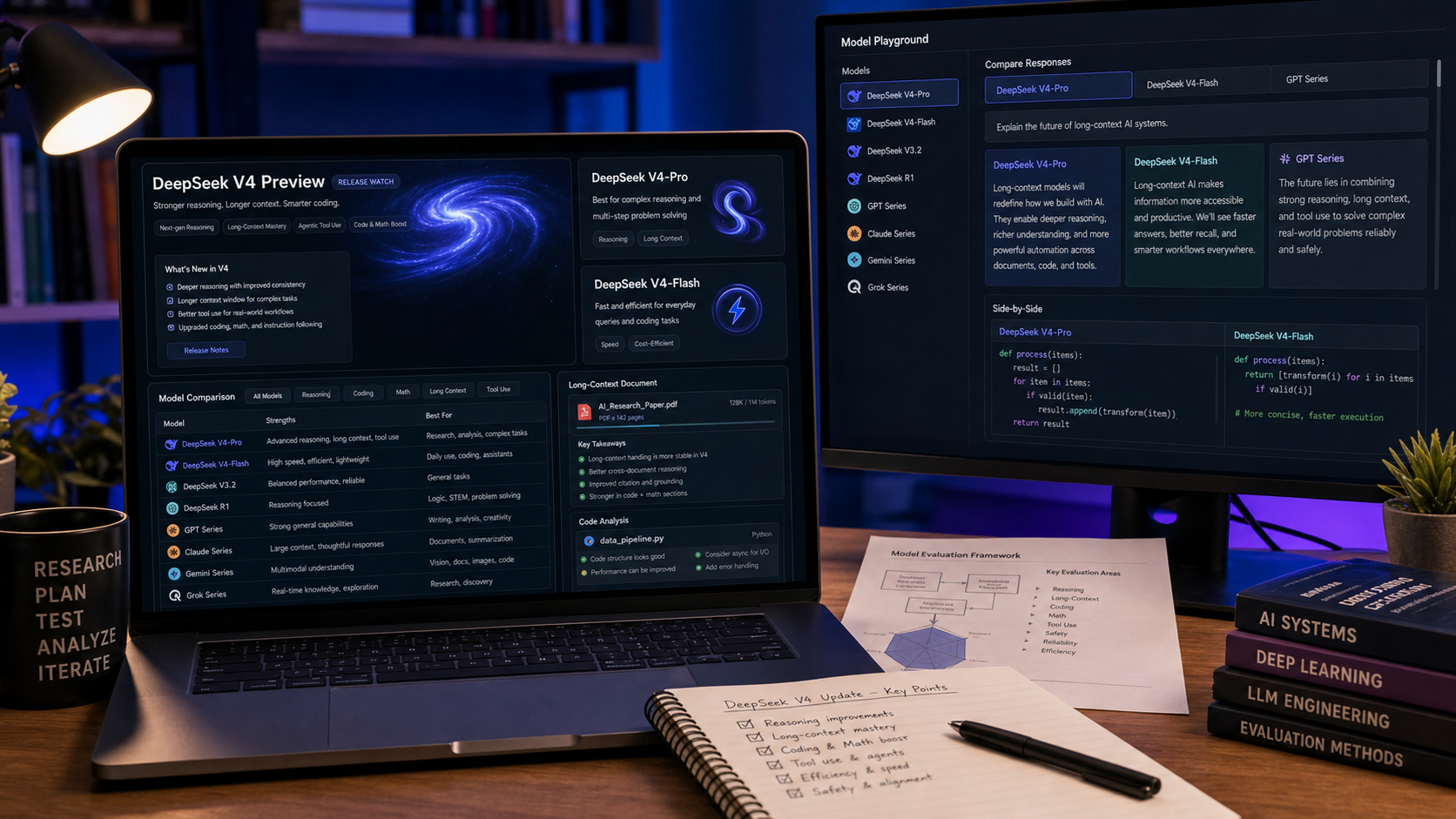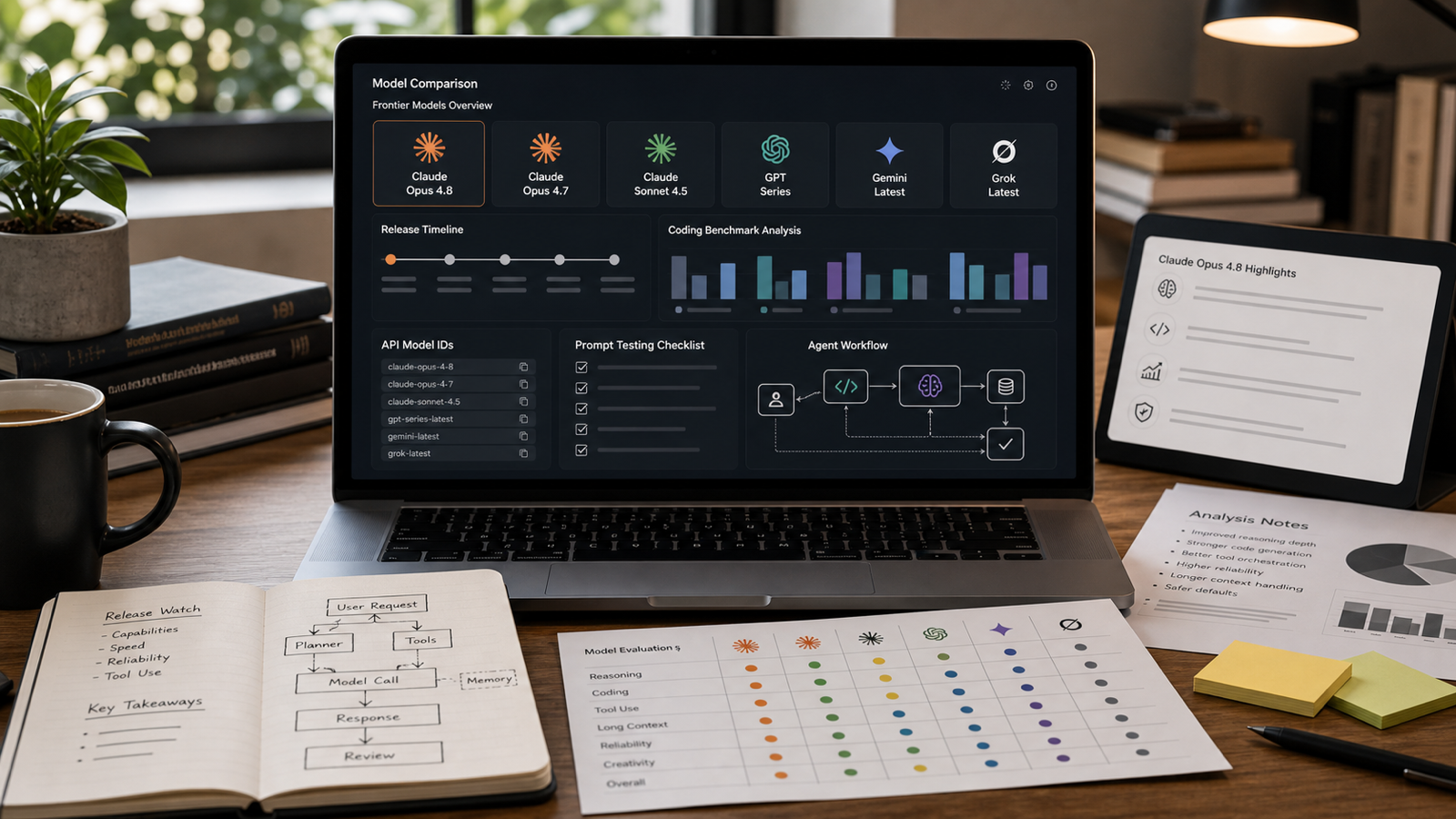
Bản phát hành Claude Opus 4.8 là có thật: Anthropic đã chính thức công bố Claude Opus 4.8 vào ngày 28 tháng 5, 2026. Bản cập nhật này quan trọng vì định vị Opus 4.8 như một mô hình mạnh hơn cho lập trình, suy luận, làm việc với ngữ cảnh dài, sử dụng công cụ và các quy trình agentic, đồng thời giữ cho phần ngôn ngữ về giá, quyền truy cập và các tuyên bố benchmark bám sát tài liệu chính thức của Anthropic thay vì tin đồn.
Để thử nghiệm thực tế, Chat4O AI hữu ích như một nền tảng quy trình làm việc đa mô hình vì nó cho người dùng một nơi để so sánh kiểu làm việc theo phong cách Claude với GPT, Gemini, Grok, DeepSeek và các họ mô hình khác. Tuy nhiên, quyền truy cập trực tiếp Claude Opus 4.8 trên Chat4O cần được xác minh trên danh sách mô hình trực tiếp trước khi khẳng định là có. Cho đến khi có một trang Opus 4.8 trực tiếp, đường đi phù hợp trên Chat4O là thử các quy trình Claude thông qua những trang như Claude Sonnet 4.5 trên Chat4O và nội dung liên quan đến các mô hình Claude khác.

Trả lời nhanh: Bản phát hành Claude Opus 4.8 có gì?
Claude Opus 4.8 là bản cập nhật Opus ngày 28 tháng 5, 2026 của Anthropic dành cho suy luận chuyên nghiệp, lập trình và các quy trình agent. Thông báo chính thức mô tả đây là một nâng cấp so với Claude Opus 4.7 với năng lực lập trình và hiệu suất tác vụ dài hơi mạnh hơn, hành vi cộng tác tốt hơn, và tiếp tục hỗ trợ các trường hợp sử dụng chuyên nghiệp cho nhà phát triển và doanh nghiệp.
Điểm quan sát quan trọng nhất khi theo dõi phát hành là Opus 4.8 không chỉ là một bản cập nhật chat thông thường. Tài liệu của Anthropic định vị đây là mô hình mạnh nhất cho “các agent phức tạp, lập trình và suy luận”, đồng thời cung cấp một model ID API đã được ghi nhận: claude-opus-4-8. Điều này quan trọng với nhà phát triển vì tên mô hình, hành vi prompt caching, fast mode và các ràng buộc API ảnh hưởng đến cách các nhóm kiểm thử và triển khai mô hình.
Với người dùng hằng ngày, điểm rút ra thực tiễn đơn giản hơn. Claude Opus 4.8 đáng theo dõi nếu công việc của bạn liên quan đến review code khó, lập kế hoạch kiến trúc, tổng hợp nghiên cứu, thiết kế agent nhiều bước, hoặc tài liệu dài nơi mô hình phải giữ ngữ cảnh và xử lý mơ hồ. Nếu bạn chủ yếu cần chat nhanh hằng ngày, soạn thảo, hoặc phân tích nhẹ, Claude Sonnet 4.5 hoặc một mô hình khác có thể vẫn là điểm khởi đầu nhạy chi phí hơn.
Trước khi đăng bất kỳ khẳng định cố định nào về quyền truy cập, hãy kiểm tra các trang trực tiếp của Anthropic và Chat4O. Tính khả dụng, hỗ trợ theo khu vực, rate limit, hành vi cửa sổ ngữ cảnh, quy tắc prompt caching, fast mode và hỗ trợ nền tảng có thể thay đổi.

Tính năng Claude Opus 4.8: Lập trình, Suy luận, Agent và Ngữ cảnh dài
Câu chuyện tính năng của Claude Opus 4.8 tập trung vào công việc chuyên nghiệp có độ tin cậy cao hơn, không phải một demo hào nhoáng đơn lẻ. Tài liệu chính thức của Anthropic nhấn mạnh cải thiện lập trình, hiệu năng agentic tốt hơn, khả năng ngữ cảnh dài, và hành vi cộng tác mạnh hơn. Đây chính là những mảng mà một bản cập nhật mô hình có thể tạo khác biệt cho các nhóm vốn đã dùng AI cho quy trình thực.
Về lập trình, bài test hữu ích nhất không phải “nó có viết được code không?”. Hầu hết các mô hình frontier đều có thể viết ra đoạn code có vẻ hợp lý. Một bài test lập trình tốt hơn cho Claude Opus 4.8 là: mô hình có thể đọc một yêu cầu thay đổi lộn xộn, rà soát các giả định, chọn lộ trình triển khai an toàn, nhận diện edge case và đề xuất test trước khi sửa code hay không. Đó là nơi suy luận mạnh hơn và hành vi agentic hữu ích hơn một câu trả lời autocomplete nhanh.
Với tác vụ ngữ cảnh dài, mấu chốt là mô hình có “bám thực” hay không. Người dùng có thể đưa cho nó một product brief, log hỗ trợ, snippet mã nguồn và một quyết định kiến trúc trước đó. Một mô hình mạnh hơn nên tách bạch sự thật đã xác nhận với giả định, giữ ràng buộc và tránh bịa ra chi tiết còn thiếu. Tài liệu chính thức mô tả Opus 4.8 trong bối cảnh cửa sổ ngữ cảnh lớn, nhưng các nhóm vẫn nên xác minh giới hạn chính xác và hành vi nền tảng theo tuyến truy cập họ chọn.
Với agent và công cụ, benchmark đúng là độ tin cậy của quy trình. Mô hình có thể lập kế hoạch một tác vụ nhiều bước, gọi công cụ chỉ khi hữu ích, phục hồi từ thất bại một phần, và bàn giao lại cho con người ở đúng điểm review hay không? Claude Opus 4.8 đáng thử nếu nhóm của bạn quan tâm đến các câu hỏi đó hơn là một câu trả lời chatbot đơn giản.

Claude Opus 4.8 vs Claude Opus 4.7: Có gì thay đổi?
Claude Opus 4.8 nên được hiểu là một nâng cấp tăng dần nhưng quan trọng so với Opus 4.7. Tài liệu “What’s New” của Anthropic liệt kê các cập nhật theo mô hình và các thay đổi hành vi API, bao gồm model ID claude-opus-4-8, tùy chọn fast mode, thay đổi prompt caching, effort mặc định và các ràng buộc kế thừa từ Opus 4.7.
So sánh nên thực hiện theo trường hợp sử dụng, không phải nhãn tiếp thị. Nếu Opus 4.7 đã xử lý tốt các tác vụ viết hằng ngày, lập trình nhẹ và phân tích ngắn, Opus 4.8 có thể không làm quy trình thường ngày của bạn thay đổi mạnh. Nếu công việc của bạn liên quan đến repo phức tạp, agent chạy dài, review tài liệu lớn hoặc các tác vụ lập trình chuyên nghiệp, Opus 4.8 có khả năng cao hơn để đáng làm pilot test.
Với người dùng API, tài liệu đặc biệt quan trọng. Anthropic mô tả fast mode là một khả năng ưu tiên tốc độ cho một số ngữ cảnh nhất định, đồng thời cũng ghi nhận các ràng buộc quanh temperature và các thiết lập sampling cho Opus 4.8. Tài liệu cũng nhắc đến yêu cầu token tối thiểu thấp hơn cho prompt caching so với hành vi trước đây. Những chi tiết này quan trọng vì cùng một prompt có thể hành xử khác nhau tùy theo thiết lập API, bề mặt truy cập và chế độ.
Hãy dùng khung so sánh này:
| Câu hỏi | Nên test gì |
|---|---|
| Opus 4.8 có tốt hơn cho lập trình không? | Chạy các bug report thật, tác vụ code review, refactor và prompt tạo test. |
| Nó có tốt hơn cho suy luận không? | Dùng memo ra quyết định, tổng hợp nghiên cứu, tài liệu dài và kiểm tra mâu thuẫn. |
| Nó có tốt hơn cho agent không? | Test quy trình công cụ nhiều bước với phục hồi lỗi và các điểm review bởi con người. |
| Có xứng đáng chi phí không? | So sánh độ thành công tác vụ, thời gian chỉnh sửa, tốc độ và chi phí token với mô hình hiện tại. |
| Sẵn sàng cho production chưa? | Xác minh giới hạn API, truy cập theo vùng, review bảo mật, logging và hỗ trợ nền tảng. |
Kết luận an toàn là Claude Opus 4.8 xứng đáng một pilot có cấu trúc, không phải chuyển đổi mù quáng.

Claude Opus 4.8 API: Model ID, Fast Mode, Prompt Caching và các thiết lập cần xác minh
Nhà phát triển nên coi Claude Opus 4.8 là một bản cập nhật cấu hình API nhiều không kém một bản phát hành mô hình. Tài liệu chính thức xác định claude-opus-4-8 là model ID và ghi nhận hành vi API có thể ảnh hưởng đến kết quả đánh giá, bao gồm fast mode, effort mặc định, prompt caching, adaptive thinking và các ràng buộc kế thừa từ Opus 4.7.
Trước khi xây dựng xoay quanh Claude Opus 4.8, hãy xác minh các mục này trong tài liệu hiện tại của Anthropic:
- Model ID hiện tại và liệu có alias hay không.
- Giá và liệu bản phát hành còn dùng cùng mức giá Opus đã niêm yết hay không.
- Cửa sổ ngữ cảnh và giới hạn đầu ra tối đa cho bề mặt nền tảng của bạn.
- Tính khả dụng của fast mode, hành vi giá và đánh đổi chất lượng.
- Quy tắc prompt caching và ngưỡng token tối thiểu.
- Các thiết lập sampling được hỗ trợ, thiết lập effort và hành vi dùng công cụ.
- Khả dụng theo khu vực, quyền truy cập doanh nghiệp, chính sách dữ liệu và giới hạn theo nền tảng.
Bước xác minh này không phải việc làm cho có. Nó bảo vệ các nhóm khỏi so sánh mô hình một cách thiếu công bằng. Ví dụ, một prompt chạy với prompt caching, fast mode, giới hạn đầu ra khác, hoặc một bề mặt khác có thể trông như khác biệt chất lượng mô hình trong khi thực tế là khác biệt cấu hình.
Bài test API tốt nhất là có thể lặp lại. Tạo một bộ benchmark nhỏ từ chính công việc của bạn: code review, phân loại bug (bug triage), tóm tắt nghiên cứu, suy luận bảng tính, phân tích tài liệu dài và một tác vụ lập kế hoạch agent. Chạy cùng các tác vụ đó trên Opus 4.8, Sonnet 4.5, mô hình GPT hiện tại của bạn và các ứng viên khác. Chấm điểm không chỉ chất lượng câu trả lời mà còn thời gian chỉnh sửa, rủi ro hallucination, độ trễ và độ nhạy chi phí.

Cách test Claude AI trên Chat4O mà không “quá đà” về quyền truy cập Opus 4.8
Chat4O AI phù hợp nhất trong bài viết này với vai trò nền tảng thử nghiệm đa mô hình thực tế, không phải là nơi được xác nhận có quyền truy cập trực tiếp Claude Opus 4.8 trừ khi một trang mô hình trực tiếp xuất hiện trên site đang hoạt động. Sự phân biệt đó quan trọng cho độ tin cậy. Độc giả có thể dùng Chat4O để so sánh các quy trình theo phong cách Claude và các mô hình liên quan, đồng thời theo dõi xem một trang Claude Opus 4.8 có trở nên khả dụng hay không.
Bắt đầu với Claude Sonnet 4.5 trên Chat4O nếu bạn muốn một quy trình suy luận và lập trình theo phong cách Claude hiện có trên nền tảng. Chat4O cũng liệt kê hoặc tham chiếu các trang Claude cũ hơn như Claude 4 Sonnet và Claude 3.7 Sonnet, giúp người dùng cảm nhận quy trình của họ Claude qua các phiên bản. Để so sánh rộng hơn, định vị nền tảng của Chat4O hỗ trợ test qua GPT, Gemini, Grok, DeepSeek và các mô hình AI khác.
Hãy dùng Chat4O để so sánh quy trình thay vì đưa ra tuyên bố benchmark cuối cùng. Một bài test nền tảng tốt sẽ đặt các câu hỏi như:
- Mô hình nào làm theo hướng dẫn lập trình của tôi với ít chỉnh sửa nhất?
- Mô hình nào xử lý ngữ cảnh dài mà không đánh rơi các ràng buộc then chốt?
- Mô hình nào nhanh nhất cho soạn thảo hằng ngày?
- Mô hình nào ghi chú rõ ràng nhất về mức độ bất định của nghiên cứu?
- Mô hình nào làm tốt nhất cho lập kế hoạch agent và quy trình công cụ?
Khi viết về Claude AI trên Chat4O, hãy dùng ngôn ngữ thận trọng: “thử các quy trình theo phong cách Claude”, “test các mô hình Claude hiện có”, hoặc “theo dõi khả năng có Claude Opus trong tương lai”. Tránh nói “dùng Claude Opus 4.8 trên Chat4O” trừ khi một trang trực tiếp được mở và xác minh.

Claude Opus 4.8 vs GPT, Gemini, Grok và các mô hình frontier khác
So sánh Claude Opus 4.8 vs GPT nên dựa trên độ phù hợp quy trình, không phải tuyên bố “mô hình tốt nhất” cho mọi thứ. Nhà phát triển, nhà phân tích, người viết, nhà nghiên cứu và người xây automation thường cần các thế mạnh khác nhau, nên một mô hình thắng tác vụ này có thể không phải lựa chọn tốt nhất cho tác vụ khác.
Dùng Claude Opus 4.8 khi tác vụ cần suy luận cẩn trọng, lập trình phức tạp, phân tích ngữ cảnh dài hoặc lập kế hoạch agent. Dùng các mô hình GPT khi quy trình hiện tại, hệ sinh thái công cụ hoặc tích hợp sản phẩm của bạn đã phụ thuộc vào chúng và chúng thể hiện tốt trong các bài test nội bộ. Dùng Gemini khi quyền truy cập hệ sinh thái Google, quy trình đa phương thức hoặc tích hợp workspace quan trọng. Dùng Grok khi trường hợp sử dụng của bạn hưởng lợi từ bề mặt sản phẩm của mô hình đó hoặc các quy trình kiểu “thời gian thực”. Dùng DeepSeek hoặc các mô hình khác khi chi phí, hành vi open-weight hoặc các ràng buộc kỹ thuật cụ thể quan trọng.
Phương pháp so sánh mạnh nhất là một rubric:
| Tiêu chí | Vì sao quan trọng |
|---|---|
| Chất lượng suy luận | Mô hình có tách bạch sự thật, giả định và mức độ bất định không? |
| Độ tin cậy khi lập trình | Nó có tạo kế hoạch an toàn, patch hữu ích và test liên quan không? |
| Hành vi ngữ cảnh dài | Nó có giữ ràng buộc xuyên suốt tài liệu lớn hoặc codebase không? |
| Tốc độ | Độ trễ có chấp nhận được cho quy trình người dùng không? |
| Độ nhạy chi phí | Cải thiện chất lượng có xứng đáng với chi tiêu không? |
| Độ tin cậy của agent | Nó có thể lập kế hoạch, dùng công cụ, phục hồi lỗi và yêu cầu review không? |
| Độ phù hợp nền tảng | Nó có sẵn ở nơi đội của bạn thực sự làm việc không? |
Đây là nơi Chat4O hữu ích: nó cho các nhóm một nơi thực tế để so sánh các quy trình mô hình đang khả dụng trước khi họ cam kết với một API, gói thuê bao hoặc quy trình production cụ thể.

Công thức prompt và các prompt test Claude Opus 4.8 có thể copy dùng ngay
Các bài test prompt tốt nhất cho Claude Opus 4.8 nên phản ánh công việc thật, không phải câu đố nhân tạo. Một prompt tốt cung cấp cho mô hình loại tác vụ rõ ràng, bối cảnh, vai trò, định dạng đầu ra, độ sâu suy luận và ràng buộc. Điều đó cho phép bạn đánh giá liệu mô hình có hữu ích trong quy trình của bạn không.
Dùng công thức prompt tái sử dụng này:
Dùng suy luận theo phong cách Claude Opus 4.8 cho [loại tác vụ]. Mục tiêu: [kết quả cụ thể]. Ngữ cảnh: [bối cảnh, tệp, codebase, dữ liệu, ràng buộc]. Vai trò: hành xử như [lập trình viên/nhà phân tích nghiên cứu/biên tập viên/chiến lược gia/người thiết kế agent]. Định dạng đầu ra: [kế hoạch từng bước, bản vá mã, bảng, báo cáo, checklist, memo quyết định]. Độ sâu suy luận: [nhanh / tiêu chuẩn / sâu]. Ràng buộc: xác minh giả định, đánh dấu mức độ bất định, chỉ hỏi những câu hỏi thiết yếu, tránh khẳng định không có căn cứ, và đưa ra các bước tiếp theo có thể kiểm chứng.
Copy và điều chỉnh các prompt sau:
- Hãy review yêu cầu thay đổi codebase này như một kỹ sư cấp cao. Xác định lộ trình triển khai an toàn nhất, các edge case có khả năng xảy ra, các file cần kiểm tra, các test cần thêm và rủi ro trước khi viết code. Xuất ra một kế hoạch kỹ thuật từng bước.
- Phân tích bug report này và đề xuất chiến lược debug. Tách bạch sự thật đã xác nhận với giả định, liệt kê các nguyên nhân gốc có khả năng, gợi ý log hoặc test cần chạy và khuyến nghị bản sửa nhỏ nhất nhưng an toàn.
- Refactor hàm này để dễ đọc và dễ bảo trì. Giữ nguyên hành vi, giải thích các thay đổi, chỉ thêm comment khi thực sự hữu ích và kèm test case cho các điều kiện biên.
- So sánh Claude Opus 4.8, Claude Sonnet 4.5, GPT-5.5 và Gemini cho quy trình của tôi. Trường hợp sử dụng của tôi là [mô tả trường hợp sử dụng]. Xếp hạng theo suy luận, lập trình, độ nhạy chi phí, tốc độ và độ tin cậy ngữ cảnh dài.
- Biến câu hỏi nghiên cứu còn thô này thành một kế hoạch nghiên cứu có cấu trúc. Bao gồm câu hỏi con, từ khóa tìm kiếm, loại nguồn, bước xác minh, thiên lệch có thể có và dàn ý cho báo cáo cuối.
- Review tài liệu dài này và trích xuất các luận điểm chính, bằng chứng yếu, mâu thuẫn, trích dẫn còn thiếu và các chỉnh sửa đề xuất. Giữ đầu ra ngắn gọn nhưng cụ thể.
- Hãy hành xử như một kiến trúc sư AI agent. Thiết kế một quy trình nhiều bước cho [tác vụ], bao gồm trigger, công cụ, nhu cầu bộ nhớ, kiểm tra an toàn, chế độ lỗi và các điểm review bởi con người.
- Viết một memo quyết định về việc liệu đội của chúng tôi có nên test Claude Opus 4.8 hay không. Bao gồm lợi ích tiềm năng, rủi ro, cân nhắc chi phí, lo ngại bảo mật, lưu ý về benchmark và tiêu chí pilot-test.
- Viết một kế hoạch test prompt để so sánh Claude Opus 4.8 với mô hình hiện tại của chúng tôi. Bao gồm 10 tác vụ đại diện, tiêu chí chấm điểm, các ca thất bại và rubric review.
- Viết lại phần giải thích kỹ thuật này cho lãnh đạo. Giữ nguyên độ chính xác, bỏ thuật ngữ khó, nêu bật tác động kinh doanh và thêm một mục rủi ro ngắn.
Chỉ chạy các prompt này trên nhiều mô hình sau khi đã loại bỏ dữ liệu riêng tư. Với sử dụng trong nhóm, hãy giữ một rubric review để mọi mô hình được chấm theo cùng tiêu chí.

FAQ và khuyến nghị cuối cùng
Claude Opus 4.8 đã được phát hành chính thức chưa?
Có. Anthropic đã chính thức công bố Claude Opus 4.8 vào ngày 28 tháng 5, 2026. Hãy dùng thông báo của Anthropic và tài liệu nền tảng làm nguồn chính cho chi tiết phát hành, model ID, hành vi API và các ràng buộc hiện tại.
Model ID API của Claude Opus 4.8 là gì?
Tài liệu của Anthropic xác định model ID là claude-opus-4-8. Nhà phát triển nên xác minh trang tổng quan mô hình hiện tại và tài liệu “What’s New” trước khi triển khai vì alias, hỗ trợ nền tảng, giá và thiết lập có thể thay đổi.
Claude Opus 4.8 có tốt hơn Claude Opus 4.7 không?
Anthropic giới thiệu Opus 4.8 là một nâng cấp so với Opus 4.7, đặc biệt cho lập trình, suy luận, cộng tác và các quy trình chuyên nghiệp. Câu trả lời tốt nhất cho đội của bạn phụ thuộc vào pilot test dùng chính code, tài liệu, dữ liệu và tác vụ agent của bạn.
Tôi có thể dùng Claude Opus 4.8 trên Chat4O AI không?
Đừng giả định có quyền truy cập trực tiếp Opus 4.8 trên Chat4O trừ khi một trang mô hình Claude Opus 4.8 trực tiếp hoặc một mục trong danh sách mô hình được xác minh. Chat4O vẫn hữu ích để test các quy trình theo phong cách Claude hiện có, bao gồm Claude Sonnet 4.5, và so sánh Claude với GPT, Gemini, Grok và các mô hình khác.
Nhà phát triển nên test gì trước tiên?
Bắt đầu với code review, phân loại bug (bug triage), refactor, lập kế hoạch kiến trúc và thiết kế quy trình agent. Các tác vụ này cho thấy liệu Claude Opus 4.8 có cải thiện không chỉ độ trôi chảy câu trả lời, mà còn chất lượng lập kế hoạch, cách xử lý bất định, gợi ý test và lựa chọn triển khai an toàn.
Kết luận
Bản phát hành Claude Opus 4.8 quan trọng vì nó đẩy Claude tiến sâu hơn vào lập trình chuyên nghiệp, suy luận, công việc agentic và các quy trình ngữ cảnh dài. Bước tiếp theo đúng đắn không phải là chấp nhận các tuyên bố “mô hình tốt nhất” một cách rộng rãi, mà là chạy một pilot cẩn trọng: xác minh tài liệu hiện tại của Anthropic, test các prompt đại diện, so sánh Claude AI hiện có trên Chat4O với GPT, Gemini, Grok và các mô hình khác, rồi quyết định dựa trên độ tin cậy, chi phí, tốc độ và độ phù hợp quy trình.