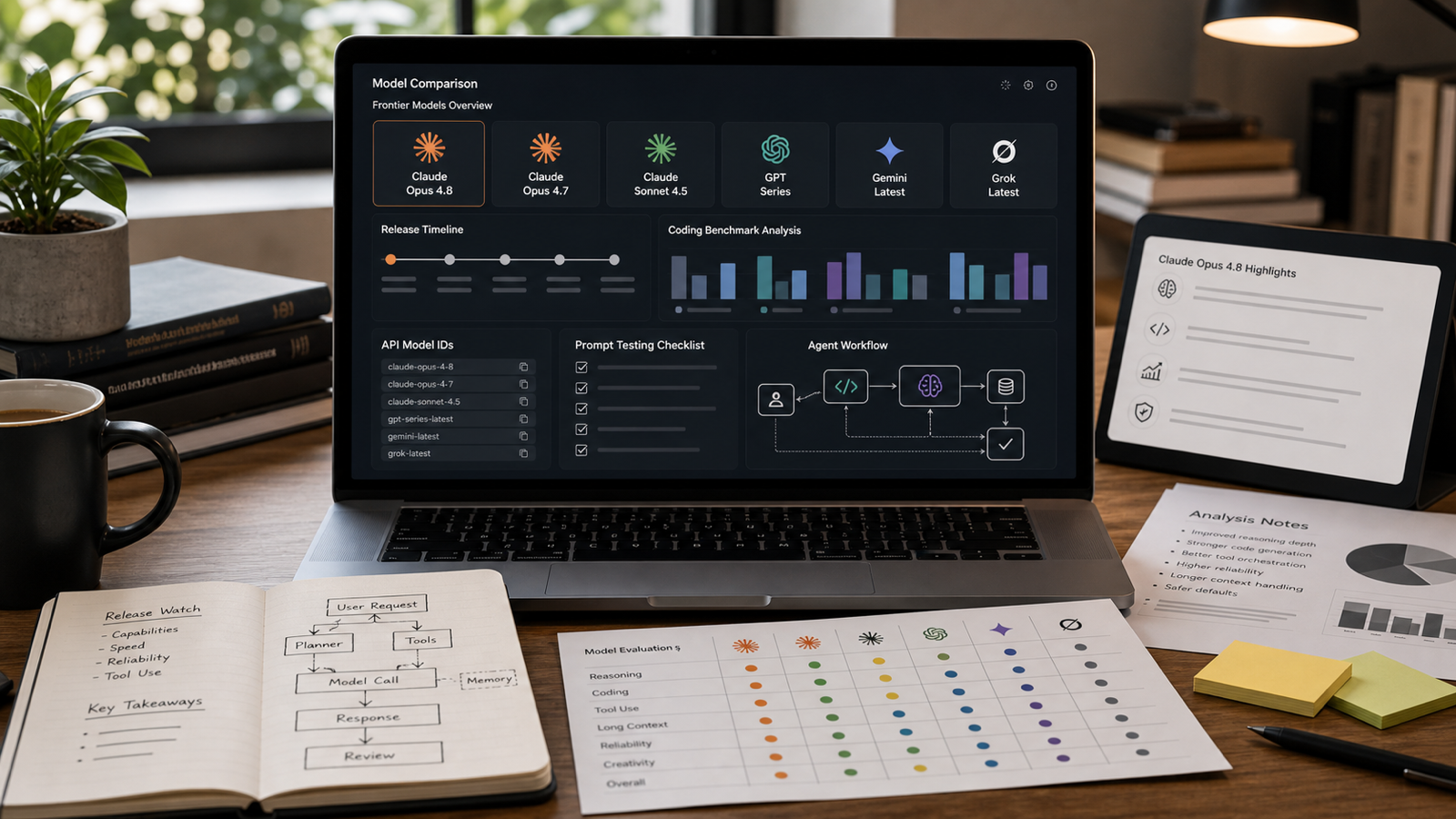
إصدار Claude Opus 4.8 حقيقي: أعلنت Anthropic رسميًا عن Claude Opus 4.8 في 28 مايو 2026. وتكمن أهمية التحديث في أنه يضع Opus 4.8 كنموذج أقوى للبرمجة، والاستدلال، والعمل بسياق طويل، واستخدام الأدوات، وتدفّقات العمل القائمة على الوكلاء (Agentic)، مع الإبقاء على اللغة المتعلقة بالتسعير وإمكانية الوصول وادعاءات المعايير (Benchmarks) مرتبطة بوثائق Anthropic الرسمية بدلًا من الشائعات.
للاختبار العملي، يُعدّ Chat4O AI مفيدًا كمنصة سير عمل متعددة النماذج لأنه يمنح المستخدمين مكانًا لمقارنة أسلوب عمل Claude مع GPT وGemini وGrok وDeepSeek وعائلات نماذج أخرى. ومع ذلك، يجب التحقق من إتاحة الوصول المباشر إلى Claude Opus 4.8 على Chat4O عبر قائمة النماذج الحية قبل الادعاء بتوفره. وإلى أن تصبح صفحة Opus 4.8 المباشرة متاحة، فإن المسار المناسب في Chat4O هو اختبار تدفقات عمل Claude عبر صفحات مثل Claude Sonnet 4.5 على Chat4O ومحتوى نماذج Claude ذات الصلة.

إجابة سريعة: ماذا تضمّن إصدار Claude Opus 4.8؟
Claude Opus 4.8 هو تحديث Opus الصادر عن Anthropic بتاريخ 28 مايو 2026 والموجّه للاستدلال الاحترافي والبرمجة وتدفّقات عمل الوكلاء. ويعرضه الإعلان الرسمي على أنه ترقية مقارنةً بـ Claude Opus 4.7 مع أداء أقوى في البرمجة والمهام طويلة التشغيل، وسلوك تعاون أفضل، واستمرار دعم حالات الاستخدام الاحترافية للمطورين والمؤسسات.
أهم نقطة يجب مراقبتها في الإصدار هي أن Opus 4.8 ليس مجرد تحديث دردشة عادي. فوثائق Anthropic تضعه بوصفه أقوى نموذج لـ “الوكلاء المعقّدين، والبرمجة، والاستدلال”، كما توفّر معرّف نموذج API موثّقًا: claude-opus-4-8. وهذا مهم للمطورين لأن أسماء النماذج، وسلوك التخزين المؤقت للمطالبات (Prompt Caching)، ووضع السرعة (Fast Mode)، وقيود واجهة API تؤثر في كيفية اختبار الفرق للنموذج ونشره.
بالنسبة للمستخدمين اليوميين، الخلاصة العملية أبسط. يجدر تتبّع Claude Opus 4.8 إذا كانت مهامك تتضمن مراجعة شيفرة صعبة، وتخطيط بنية/معمارية، وتلخيص أبحاث، وتصميم وكلاء متعدد الخطوات، أو مستندات طويلة حيث يجب على النموذج الحفاظ على السياق والتعامل مع الغموض. وإذا كنت تحتاج غالبًا إلى دردشة يومية سريعة، أو صياغة نصوص، أو تحليل أخف، فقد يظل Claude Sonnet 4.5 أو نموذج آخر نقطة انطلاق أكثر حساسية للتكلفة.
قبل نشر أي ادعاء ثابت حول الإتاحة، تحقّق من صفحات Anthropic وChat4O الحية. يمكن أن تتغير الإتاحة، ودعم المناطق، وحدود المعدّل (Rate Limits)، وسلوك نافذة السياق، وقواعد التخزين المؤقت للمطالبات، ووضع السرعة، ودعم المنصات.

ميزات Claude Opus 4.8: البرمجة، والاستدلال، والوكلاء، والسياق الطويل
تركّز قصة ميزات Claude Opus 4.8 على عمل احترافي أعلى موثوقية، وليس على عرض واحد مبهرج. تؤكد مواد Anthropic الرسمية على تحسينات في البرمجة، وأداء أفضل للوكلاء، وقدرة سياق طويل، وسلوك تعاون أقوى. وهذه هي المجالات تحديدًا التي قد يحدث فيها تحديث نموذج فرقًا لدى الفرق التي تستخدم الذكاء الاصطناعي بالفعل في سير عمل حقيقي.
في البرمجة، الاختبار الأكثر فائدة ليس “هل يستطيع كتابة شيفرة؟” فمعظم النماذج المتقدمة يمكنها كتابة شيفرة تبدو مقنعة. اختبار Claude Opus 4.8 الأفضل في البرمجة يسأل: هل يمكن للنموذج قراءة طلب تغيير فوضوي، وفحص الافتراضات، واختيار مسار تنفيذ آمن، وتحديد الحالات الطرفية، واقتراح اختبارات قبل التعديل؟ هنا يصبح الاستدلال الأقوى والسلوك الوكيلي أكثر فائدة من إجابة إكمال تلقائي سريعة.
في مهام السياق الطويل، المفتاح هو ما إذا كان النموذج يبقى منضبطًا بالحقائق. قد يزوّده المستخدم بملخص منتج، وسجلات دعم، ومقاطع مصدر، وقرار معماري سابق. ينبغي للنموذج الأقوى أن يفصل الحقائق المؤكدة عن الافتراضات، ويحافظ على القيود، ويتجنب اختراع تفاصيل مفقودة. تصف الوثائق الرسمية Opus 4.8 ضمن سياق نوافذ سياق كبيرة، لكن يجب على الفرق مع ذلك التحقق من الحدود الدقيقة وسلوك المنصة لمسار الوصول الذي تختاره.
بالنسبة للوكلاء والأدوات، المعيار الصحيح هو موثوقية سير العمل. هل يمكن للنموذج تخطيط مهمة متعددة الخطوات، واستدعاء الأدوات فقط عندما يكون ذلك مفيدًا، والتعافي من فشل جزئي، وتسليم العمل إلى إنسان عند نقطة المراجعة المناسبة؟ يجدر اختبار Claude Opus 4.8 إذا كانت هذه الأسئلة أهم لفريقك من مجرد إجابة روبوت دردشة بسيطة.

Claude Opus 4.8 مقابل Claude Opus 4.7: ما الذي تغيّر؟
ينبغي فهم Claude Opus 4.8 على أنه ترقية تدريجية لكنها مهمة مقارنةً بـ Opus 4.7. تسرد وثائق Anthropic ضمن قسم “ما الجديد” تحديثات خاصة بالنموذج وتغييرات في سلوك واجهة API، بما في ذلك معرّف النموذج claude-opus-4-8، وخيار وضع السرعة (Fast Mode)، وتغييرات التخزين المؤقت للمطالبات، والافتراضات الافتراضية لمستوى الجهد (Effort Defaults)، والقيود الموروثة من Opus 4.7.
ينبغي إجراء المقارنة عبر حالات الاستخدام، لا عبر ملصقات التسويق. إذا كان Opus 4.7 يتعامل بالفعل مع كتاباتك اليومية، والبرمجة الخفيفة، ومهام التحليل القصيرة بشكل جيد، فقد لا يغير Opus 4.8 سير عملك اليومي جذريًا. أما إذا كان عملك يتضمن مستودعات معقّدة، أو وكلاء يعملون لفترات طويلة، أو مراجعة مستندات كبيرة، أو مهام برمجة احترافية، فمن الأرجح أن يبرر Opus 4.8 اختبارًا تجريبيًا (Pilot).
لمستخدمي API، الوثائق مهمة على نحو خاص. تصف Anthropic وضع السرعة بوصفه قدرة تعطي الأولوية للسرعة في سياقات معينة، مع توثيق قيود حول إعدادات الحرارة (Temperature) وأخذ العينات (Sampling) لـ Opus 4.8. كما تذكر الوثائق متطلبات حد أدنى أقل من التوكنات للتخزين المؤقت للمطالبات مقارنةً بسلوك سابق. هذه التفاصيل مهمة لأن نفس المطالبة يمكن أن تتصرف بشكل مختلف اعتمادًا على إعدادات API والواجهة (Surface) والوضع.
استخدم إطار المقارنة هذا:
| السؤال | ما الذي يجب اختباره |
|---|---|
| هل Opus 4.8 أفضل للبرمجة؟ | شغّل تقارير أخطاء حقيقية، ومهام مراجعة شيفرة، وإعادة هيكلة، ومطالبات توليد اختبارات. |
| هل هو أفضل للاستدلال؟ | استخدم مذكرات قرار، وتلخيص أبحاث، ومستندات طويلة، وفحوصات تناقض. |
| هل هو أفضل للوكلاء؟ | اختبر سير عمل أدوات متعددة الخطوات مع التعافي من الفشل ونقاط مراجعة بشرية. |
| هل يستحق التكلفة؟ | قارن نجاح المهمة، وزمن المراجعة، والسرعة، وتكلفة التوكنات مقابل نموذجك الحالي. |
| هل هو جاهز للإنتاج؟ | تحقّق من حدود API، والوصول حسب المنطقة، ومراجعة الأمان، والتسجيل (Logging)، ودعم المنصة. |
الخلاصة الآمنة: Claude Opus 4.8 يستحق تجربة تجريبية منظمة، لا انتقالًا أعمى.

واجهة Claude Opus 4.8 API: معرّف النموذج، وضع السرعة، التخزين المؤقت للمطالبات، وإعدادات يجب التحقق منها
ينبغي على المطورين التعامل مع Claude Opus 4.8 كتحديث لإعدادات واجهة API بقدر ما هو إصدار نموذج. تحدد الوثائق الرسمية claude-opus-4-8 بوصفه معرّف النموذج وتوثّق سلوك API الذي قد يؤثر في نتائج التقييم، بما في ذلك وضع السرعة، والافتراضات الافتراضية للجهد، والتخزين المؤقت للمطالبات، والتفكير التكيفي (Adaptive Thinking)، والقيود الموروثة من Opus 4.7.
قبل البناء حول Claude Opus 4.8، تحقّق من العناصر التالية في وثائق Anthropic الحالية:
- معرّف النموذج الحالي وما إذا كانت هناك أسماء مستعارة (Aliases) متاحة.
- التسعير وما إذا كان الإصدار ما يزال يستخدم تسعير Opus المدرج نفسه.
- نافذة السياق وحدود الإخراج القصوى لواجهة منصتك.
- توفر وضع السرعة، وسلوك التسعير، ومفاضلات الجودة.
- قواعد التخزين المؤقت للمطالبات وحدود الحد الأدنى للتوكنات.
- إعدادات أخذ العينات المدعومة، وإعدادات الجهد، وسلوك استخدام الأدوات.
- الإتاحة حسب المنطقة، ووصول المؤسسات، وسياسات البيانات، والقيود الخاصة بالمنصة.
خطوة التحقق هذه ليست عملاً شكليًا. فهي تحمي الفرق من مقارنة النماذج بشكل غير عادل. على سبيل المثال، تشغيل مطالبة مع التخزين المؤقت للمطالبات أو وضع السرعة أو حدود إخراج مختلفة أو عبر واجهة مختلفة قد يبدو كأنه فرق في جودة النموذج، بينما هو في الواقع فرق في الإعدادات.
أفضل اختبار API هو القابل للتكرار. أنشئ مجموعة معايير صغيرة من عملك الخاص: مراجعة شيفرة، وفرز أخطاء (Bug Triage)، وملخص بحث، واستدلال على جداول بيانات، وتحليل مستند طويل، ومهمة تخطيط وكيل. شغّل المهام نفسها على Opus 4.8 وSonnet 4.5 ونموذج GPT الحالي لديك وأي مرشح آخر. قيّم ليس فقط جودة الإجابة، بل أيضًا وقت التصحيح، وخطر الهلوسة، وزمن الاستجابة (Latency)، والحساسية للتكلفة.

كيفية اختبار Claude AI على Chat4O دون المبالغة في الادعاء بإتاحة Opus 4.8
من الأفضل تقديم Chat4O AI في هذا المقال بوصفه منصة عملية لاختبار متعدد النماذج، لا بوصفه وصولًا مباشرًا مؤكّدًا إلى Claude Opus 4.8 ما لم تكن صفحة نموذج مباشرة مرئية على الموقع الحي. هذا التفريق مهم للثقة. يمكن للقراء استخدام Chat4O لمقارنة تدفقات عمل شبيهة بـ Claude ونماذج ذات صلة، مع تتبع ما إذا كانت صفحة Claude Opus 4.8 ستصبح متاحة.
ابدأ بـ Claude Sonnet 4.5 على Chat4O إذا كنت تريد سير عمل حاليًا بأسلوب Claude للاستدلال والبرمجة على المنصة. كما يسرد Chat4O أو يشير إلى صفحات Claude أقدم مثل Claude 4 Sonnet وClaude 3.7 Sonnet، ما يمكن أن يساعد المستخدمين على فهم كيف يبدو سير عمل عائلة Claude عبر الإصدارات. وللمقارنة الأوسع، يدعم تموضع منصة Chat4O الاختبار عبر GPT وGemini وGrok وDeepSeek ونماذج ذكاء اصطناعي أخرى.
استخدم Chat4O لمقارنة سير العمل بدلًا من ادعاءات المعايير النهائية. اختبار منصة جيد يطرح أسئلة مثل:
- أي نموذج يتبع تعليمات البرمجة لدي بأقل قدر من التصحيح؟
- أي نموذج يتعامل مع سياق طويل دون فقدان القيود الرئيسية؟
- أي نموذج هو الأسرع للصياغة اليومية؟
- أي نموذج يقدّم أوضح ملاحظات عدم اليقين البحثي؟
- أي نموذج يعمل أفضل لتخطيط الوكلاء وتدفّقات عمل الأدوات؟
عند الكتابة عن Claude AI على Chat4O، استخدم لغة دقيقة: “جرّب تدفقات عمل بأسلوب Claude”، “اختبر نماذج Claude المتاحة”، أو “تتبّع إتاحة Claude Opus مستقبلًا”. تجنب قول “استخدم Claude Opus 4.8 على Chat4O” ما لم تكن هناك صفحة مباشرة متاحة ومتحققًا منها.

Claude Opus 4.8 مقابل GPT وGemini وGrok ونماذج متقدمة أخرى
يجب أن تُبنى مقارنات Claude Opus 4.8 مقابل GPT على ملاءمة سير العمل، لا على ادعاء “أفضل نموذج” عالمي. فالمطورون والمحللون والكتّاب والباحثون وبناة الأتمتة غالبًا ما يحتاجون نقاط قوة مختلفة، لذا قد يفوز نموذج في مهمة واحدة دون أن يكون أفضل خيار لمهمة أخرى.
استخدم Claude Opus 4.8 عندما تكافئ المهمة الاستدلال المتأني، والبرمجة المعقدة، وتحليل السياق الطويل، أو تخطيط الوكلاء. استخدم نماذج GPT عندما يعتمد سير عملك الحالي أو منظومة الأدوات أو تكامل المنتج لديك عليها بالفعل وتؤدي جيدًا في اختباراتك الداخلية. استخدم Gemini عندما تكون أهمية الوصول إلى منظومة Google أو سير العمل متعدد الوسائط أو التكامل مع مساحة العمل عاملًا حاسمًا. استخدم Grok عندما تستفيد حالة الاستخدام من واجهة ذلك المنتج أو تدفقات عمل بأسلوب “الزمن الحقيقي”. استخدم DeepSeek أو نماذج أخرى عندما تهم التكلفة أو سلوك الأوزان المفتوحة (Open-Weight) أو قيود تقنية محددة.
أقوى طريقة للمقارنة هي مقياس تقييم (Rubric):
| المعيار | لماذا يهم |
|---|---|
| جودة الاستدلال | هل يستطيع النموذج فصل الحقائق والافتراضات وعدم اليقين؟ |
| موثوقية البرمجة | هل ينتج خططًا آمنة، وترقيعات مفيدة، واختبارات ذات صلة؟ |
| سلوك السياق الطويل | هل يحتفظ بالقيود عبر مستندات كبيرة أو قواعد شيفرة؟ |
| السرعة | هل زمن الاستجابة مقبول لسير عمل المستخدم؟ |
| الحساسية للتكلفة | هل يبرر تحسن الجودة الإنفاق؟ |
| موثوقية الوكيل | هل يستطيع التخطيط، واستخدام الأدوات، والتعافي من الأخطاء، وطلب المراجعة؟ |
| ملاءمة المنصة | هل هو متاح حيث يعمل فريقك فعليًا؟ |
هنا تبرز فائدة Chat4O: فهو يمنح الفرق مكانًا عمليًا لمقارنة تدفقات عمل النماذج المتاحة قبل الالتزام بواجهة API معينة أو اشتراك أو عملية إنتاج.

صيغة مطالبة (Prompt) ونصوص اختبار جاهزة لنسخها لـ Claude Opus 4.8
أفضل اختبارات مطالبة Claude Opus 4.8 ينبغي أن تعكس عملًا حقيقيًا، لا ألغازًا مصطنعة. تمنح المطالبة الجيدة النموذج نوع مهمة واضحًا، وخلفية، ودورًا، وتنسيق مخرجات، وعمق استدلال، وقيودًا. هذا يتيح لك الحكم على ما إذا كان النموذج مفيدًا في سير عملك.
استخدم صيغة المطالبة القابلة لإعادة الاستخدام هذه:
استخدم أسلوب استدلال Claude Opus 4.8 لـ [نوع المهمة]. الهدف: [نتيجة محددة]. السياق: [خلفية، ملفات، قاعدة شيفرة، بيانات، قيود]. الدور: تصرّف بصفتك [مطور/محلل أبحاث/محرر/استراتيجي/مخطط وكلاء]. تنسيق الإخراج: [خطة خطوة بخطوة، رقعة شيفرة، جدول، تقرير، قائمة تحقق، مذكرة قرار]. عمق الاستدلال: [سريع / قياسي / عميق]. القيود: تحقّق من الافتراضات، أشر إلى عدم اليقين، اسأل فقط الأسئلة الضرورية، تجنّب الادعاءات غير المدعومة، وقدّم خطوات تالية قابلة للاختبار.
انسخ وكيّف هذه المطالبات:
- راجع طلب تغيير قاعدة الشيفرة هذا كمهندس أول. حدّد مسار التنفيذ الأكثر أمانًا، والحالات الطرفية المحتملة، والملفات التي يجب تفقدها، والاختبارات التي ينبغي إضافتها، والمخاطر قبل كتابة الشيفرة. أخرج خطة هندسية خطوة بخطوة.
- حلّل تقرير الخطأ هذا واقترح استراتيجية تصحيح. افصل الحقائق المؤكدة عن الافتراضات، واسرد الأسباب الجذرية المحتملة، واقترح سجلات أو اختبارات لتشغيلها، وأوصِ بأصغر إصلاح آمن.
- أعد هيكلة هذه الدالة لتحسين الوضوح وقابلية الصيانة. حافظ على السلوك، واشرح التغييرات، وأضف تعليقات فقط عند الحاجة، وتضمّن حالات اختبار للشروط الطرفية.
- قارن Claude Opus 4.8 وClaude Sonnet 4.5 وGPT-5.5 وGemini لسير عملي. حالة استخدامي هي [صف حالة الاستخدام]. رتّبهم حسب الاستدلال، والبرمجة، والحساسية للتكلفة، والسرعة، وموثوقية السياق الطويل.
- حوّل سؤال البحث الخام هذا إلى خطة بحث منظمة. ضمّن أسئلة فرعية، ومصطلحات بحث، وأنواع مصادر، وخطوات تحقق، وانحيازات محتملة، ومخططًا للتقرير النهائي.
- راجع هذا المستند الطويل واستخرج الادعاءات الرئيسية، وضعف الأدلة، والتناقضات، والاستشهادات المفقودة، والمراجعات الموصى بها. اجعل المخرجات موجزة لكن محددة.
- تصرّف كمهندس معمارية للوكلاء الذكاء الاصطناعي. صمّم سير عمل متعدد الخطوات لـ [المهمة]، بما في ذلك المُشغِّل (Trigger)، والأدوات، واحتياجات الذاكرة، وفحوصات السلامة، وأنماط الفشل، ونقاط المراجعة البشرية.
- اكتب مذكرة قرار حول ما إذا كان ينبغي لفريقنا اختبار Claude Opus 4.8. ضمّن المنافع المحتملة، والمخاطر، واعتبارات التكلفة، ومخاوف الأمان، ومحاذير المعايير، ومعايير الاختبار التجريبي.
- اكتب خطة اختبار مطالبات لمقارنة Claude Opus 4.8 بنموذجنا الحالي. ضمّن 10 مهام تمثيلية، ومعايير تسجيل، وحالات فشل، ومقياس مراجعة.
- أعد كتابة هذا الشرح التقني للمديرين التنفيذيين. حافظ على الدقة، وأزل المصطلحات المعقدة، وأبرز الأثر على الأعمال، وأدرج قسم مخاطر قصيرًا.
شغّل هذه المطالبات عبر النماذج فقط بعد إزالة البيانات الخاصة. وللاستخدام ضمن الفريق، احتفظ بمقياس مراجعة كي يُقيَّم كل نموذج وفق المعايير نفسها.

الأسئلة الشائعة والتوصية النهائية
هل تم إصدار Claude Opus 4.8 رسميًا؟
نعم. أعلنت Anthropic رسميًا عن Claude Opus 4.8 في 28 مايو 2026. استخدم إعلان Anthropic ووثائق المنصة كمصادر أساسية لتفاصيل الإصدار، ومعرّف النموذج، وسلوك واجهة API، والقيود الحالية.
ما هو معرّف نموذج API لـ Claude Opus 4.8؟
تحدد وثائق Anthropic معرّف النموذج بأنه claude-opus-4-8. ينبغي على المطورين التحقق من نظرة عامة النموذج الحالية ووثائق “ما الجديد” قبل النشر لأن الأسماء المستعارة، ودعم المنصة، والتسعير، والإعدادات قد تتغير.
هل Claude Opus 4.8 أفضل من Claude Opus 4.7؟
تقدم Anthropic Opus 4.8 كترقية مقارنةً بـ Opus 4.7، خاصةً في البرمجة والاستدلال والتعاون وتدفّقات العمل الاحترافية. أفضل إجابة لفريقك تعتمد على اختبارات تجريبية باستخدام شيفرتك ومستنداتك وبياناتك ومهام الوكلاء الخاصة بك.
هل يمكنني استخدام Claude Opus 4.8 على Chat4O AI؟
لا تفترض توفر وصول مباشر إلى Opus 4.8 على Chat4O ما لم يتم التحقق من وجود صفحة نموذج Claude Opus 4.8 حية أو إدراج في قائمة النماذج. يظل Chat4O مفيدًا لاختبار تدفقات عمل متاحة بأسلوب Claude، بما في ذلك Claude Sonnet 4.5، ومقارنة Claude مع GPT وGemini وGrok ونماذج أخرى.
ما الذي ينبغي للمطورين اختباره أولًا؟
ابدأ بمراجعة الشيفرة، وفرز الأخطاء، وإعادة الهيكلة، وتخطيط المعمارية، وتصميم سير عمل الوكلاء. تكشف هذه المهام ما إذا كان Claude Opus 4.8 يحسن ليس فقط سلاسة الإجابة، بل جودة التخطيط، والتعامل مع عدم اليقين، واقتراح الاختبارات، وخيارات التنفيذ الآمن.
الخلاصة
إصدار Claude Opus 4.8 مهم لأنه يدفع Claude أكثر نحو البرمجة الاحترافية والاستدلال والعمل الوكيلي وتدفّقات العمل ذات السياق الطويل. الخطوة التالية الصحيحة ليست قبول ادعاءات عامة من نوع “أفضل نموذج”، بل إجراء تجربة تجريبية دقيقة: تحقّق من وثائق Anthropic الحالية، واختبر مطالبات تمثيلية، وقارن نماذج Claude AI المتاحة على Chat4O مع GPT وGemini وGrok ونماذج أخرى، ثم قرّر بناءً على الموثوقية والتكلفة والسرعة وملاءمة سير العمل.