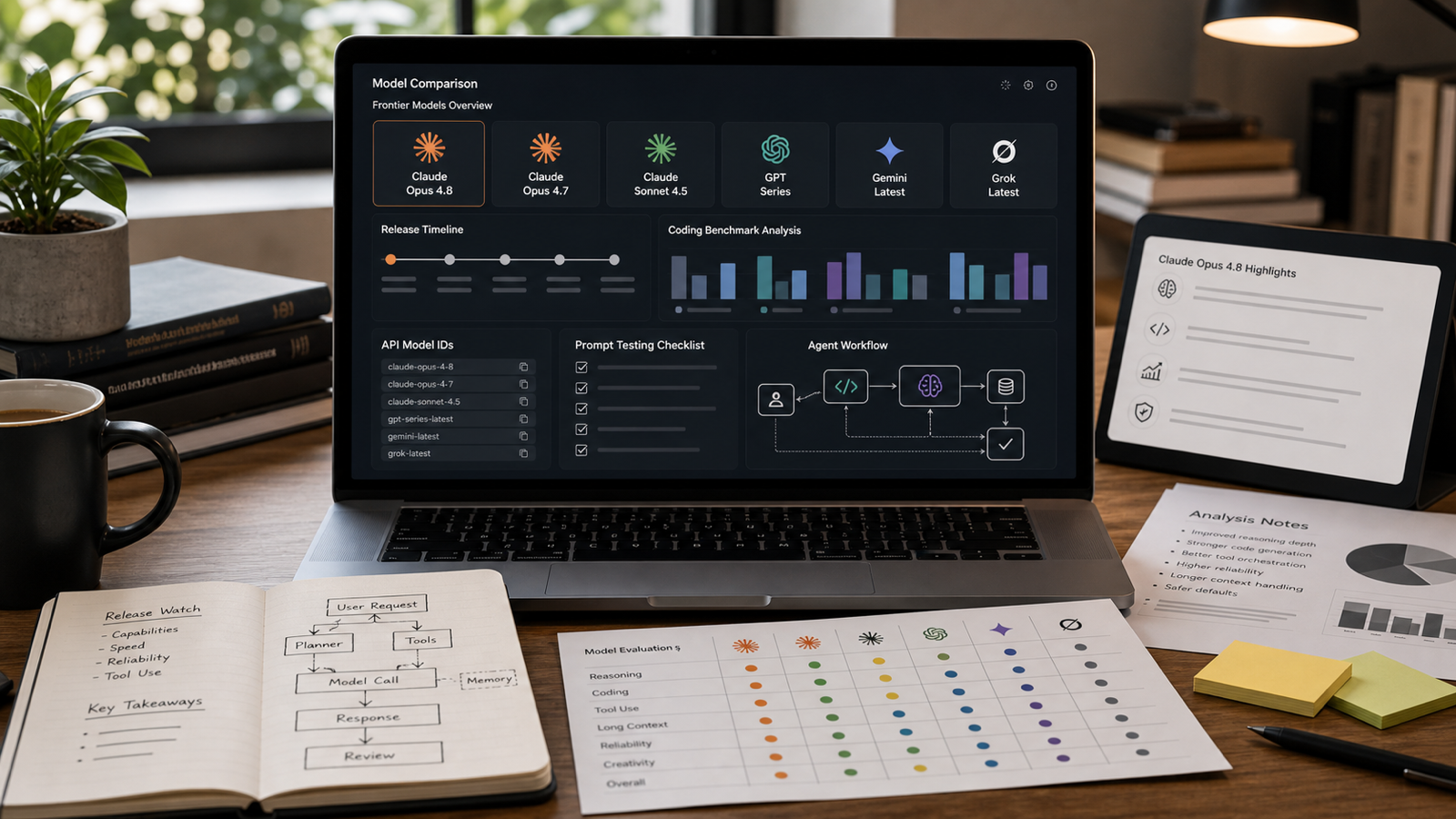
Claude Opus 4.8 的发布属实:Anthropic 已于 2026 年 5 月 28 日正式宣布 Claude Opus 4.8。此次更新之所以重要,是因为它将 Opus 4.8 定位为更强的编码、推理、长上下文工作、工具使用与代理式(agentic)工作流模型,同时在价格、访问方式与基准测试声明方面,仍以 Anthropic 官方文档为准,而非传言。
在实际测试层面,Chat4O AI 作为多模型工作流平台很有用,因为它为用户提供了一个对比 Claude 风格工作与 GPT、Gemini、Grok、DeepSeek 及其他模型家族的场所。不过,Chat4O 上是否可直接访问 Claude Opus 4.8,应在实时模型列表中核验后再声称可用。在 Opus 4.8 的直达页面上线之前,Chat4O 的相关路径是通过诸如 Chat4O 上的 Claude Sonnet 4.5 以及相关 Claude 模型内容来测试 Claude 工作流。

快速回答:Claude Opus 4.8 发布包含了什么?
Claude Opus 4.8 是 Anthropic 于 2026 年 5 月 28 日发布的 Opus 更新,面向专业推理、编码与代理工作流。官方公告将其描述为相较 Claude Opus 4.7 的升级版,具备更强的编码能力与长时任务表现、更好的协作行为,并持续支持专业开发者与企业级用例。
最重要的发布观察点在于:Opus 4.8 不只是一次轻量的聊天更新。Anthropic 文档将其定位为“复杂代理、编码与推理”的最强模型,同时还提供了已记录的 API 模型 ID:claude-opus-4-8。这对开发者很关键,因为模型名称、提示词缓存行为、快速模式以及 API 约束,会影响团队如何测试与部署该模型。
对日常用户而言,实际结论更简单:如果你的任务涉及高难度代码审查、架构规划、研究综合、多步代理设计,或需要模型保持上下文并处理歧义的长文档,那么 Claude Opus 4.8 值得关注。如果你主要需要快速的日常聊天、起草或较轻量的分析,Claude Sonnet 4.5 或其他模型可能仍是更具成本敏感性的起点。
在发布任何固定的可用性结论前,请查看 Anthropic 与 Chat4O 的实时页面。可用性、区域支持、速率限制、上下文窗口行为、提示词缓存规则、快速模式与平台支持都可能变化。

Claude Opus 4.8 功能:编码、推理、代理与长上下文
Claude Opus 4.8 的功能叙事核心在于更高可靠性的专业工作,而不是某个炫目的单一演示。Anthropic 官方材料强调编码改进、更好的代理式表现、长上下文能力以及更强的协作行为。这些正是模型更新可能对已在真实工作流中使用 AI 的团队产生影响的领域。
在编码方面,最有用的测试不是“它会不会写代码?”大多数前沿模型都能写出看似合理的代码。更好的 Claude Opus 4.8 编码测试,是看模型能否读懂杂乱的变更需求、检查隐含前提、选择安全的实现路径、识别边界情况,并在修改前提出测试建议。这正是更强推理与代理式行为比快速自动补全更有价值的地方。
在长上下文任务中,关键在于模型是否保持“有据可依”。用户可能提供产品简报、支持日志、源代码片段与既往架构决策。更强的模型应能区分已确认事实与假设、保留约束,并避免编造缺失细节。官方文档在大上下文窗口的语境下描述 Opus 4.8,但团队仍应针对所选访问路径核验确切限制与平台行为。
在代理与工具方面,合适的基准是工作流可靠性:模型能否规划多步任务、只在有价值时调用工具、从部分失败中恢复,并在合适的复核节点把工作交回给人类?如果你的团队更关心这些问题而不只是聊天式回答,那么 Claude Opus 4.8 值得测试。

Claude Opus 4.8 vs Claude Opus 4.7:有什么变化?
应将 Claude Opus 4.8 理解为相对 Opus 4.7 的渐进但重要的升级。Anthropic 的 “What’s New(更新内容)” 文档列出了模型特定更新与 API 行为变化,包括 claude-opus-4-8 模型 ID、快速模式选项、提示词缓存变更、effort 默认值,以及继承自 Opus 4.7 的约束。
比较应基于用例,而非营销标签。如果 Opus 4.7 已能很好地处理你的日常写作、轻度编码与短分析任务,Opus 4.8 可能不会显著改变日常流程。如果你的工作涉及复杂代码仓库、长时运行代理、大型文档审阅或专业编码任务,那么 Opus 4.8 更可能值得进行试点测试。
对 API 用户而言,文档尤为重要。Anthropic 将快速模式描述为在特定上下文中优先速度的能力,同时也记录了 Opus 4.8 在温度与采样设置方面的约束。文档还提到,相比早期行为,提示词缓存的最小 token 要求更低。这些细节很关键,因为同一提示词会因 API 设置、使用界面与模式不同而表现不同。
使用这套比较框架:
| 问题 | 要测试什么 |
|---|---|
| Opus 4.8 的编码更好吗? | 跑真实缺陷报告、代码审查任务、重构与测试生成提示词。 |
| 推理更好吗? | 用决策备忘录、研究综合、长文档与矛盾检查。 |
| 代理更好吗? | 测试带故障恢复与人工复核节点的多步工具工作流。 |
| 值得这个成本吗? | 将任务成功率、返工时间、速度与 token 成本对比现用模型。 |
| 适合上生产吗? | 核验 API 限额、区域访问、安全审查、日志与平台支持。 |
稳妥结论是:Claude Opus 4.8 值得进行结构化试点,而不是盲目迁移。

Claude Opus 4.8 API:模型 ID、快速模式、提示词缓存与需核验的设置
开发者应将 Claude Opus 4.8 视为一次 API 配置更新,重要性不亚于模型发布本身。官方文档标识 claude-opus-4-8 为模型 ID,并记录了可能影响评估结果的 API 行为,包括快速模式、effort 默认值、提示词缓存、自适应思考(adaptive thinking),以及继承自 Opus 4.7 的约束。
在围绕 Claude Opus 4.8 开发之前,请在 Anthropic 最新文档中核验以下事项:
- 当前模型 ID,以及是否提供别名(alias)。
- 定价,以及该版本是否仍沿用已列出的 Opus 定价。
- 你的平台入口对应的上下文窗口与最大输出限制。
- 快速模式的可用性、计费行为与质量权衡。
- 提示词缓存规则与最小 token 阈值。
- 支持的采样设置、effort 设置与工具使用行为。
- 区域可用性、企业访问、数据政策与平台特定限制。
这一步不是走形式,而是为了避免团队产生不公平对比。例如,带提示词缓存、快速模式、不同输出上限或不同入口的同一提示词运行结果,看起来像模型质量差异,实则是配置差异。
最好的 API 测试应可复现。基于你们自己的工作构建一个小型基准集:代码审查、缺陷分流、研究总结、表格推理、长文档分析与代理规划任务。用同一批任务对比 Opus 4.8、Sonnet 4.5、你们当前的 GPT 模型及其他候选模型。评分不仅看答案质量,还要看纠错时间、幻觉风险、延迟与成本敏感度。

如何在 Chat4O 上测试 Claude AI,同时不夸大 Opus 4.8 访问能力
在本文中,Chat4O AI 最适合被定位为实用的多模型测试平台,而不是“已确认可直接访问 Claude Opus 4.8”(除非在实时站点上能看到 Opus 4.8 的直达模型页)。这种区分对可信度很重要。读者可用 Chat4O 对比 Claude 风格工作流与相关模型,同时追踪 Claude Opus 4.8 页面是否上线。
如果你想在该平台上使用当前的 Claude 风格推理与编码工作流,可从 Chat4O 上的 Claude Sonnet 4.5 开始。Chat4O 也会列出或引用更早的 Claude 页面,如 Claude 4 Sonnet 与 Claude 3.7 Sonnet,帮助用户理解 Claude 家族工作流在不同版本间的手感差异。若要更广泛对比,Chat4O 的平台定位也支持在 GPT、Gemini、Grok、DeepSeek 及其他 AI 模型之间进行测试。
使用 Chat4O 做工作流对比,而不是做最终基准宣称。一个好的平台测试会问:
- 哪个模型最少需要我纠正就能遵循我的编码指令?
- 哪个模型处理长上下文时最不容易丢失关键约束?
- 哪个模型最适合日常起草且速度最快?
- 哪个模型能给出最清晰的研究不确定性说明?
- 哪个模型最适合代理规划与工具工作流?
在撰写关于 Chat4O 上 Claude AI 的内容时,请使用谨慎措辞:“尝试 Claude 风格工作流”“测试可用的 Claude 模型”“追踪未来 Claude Opus 的可用性”。除非直达页面已上线并核验,否则避免说“在 Chat4O 上使用 Claude Opus 4.8”。

Claude Opus 4.8 vs GPT、Gemini、Grok 与其他前沿模型
Claude Opus 4.8 vs GPT 的对比应基于工作流匹配度,而不是宣称“普遍最强模型”。开发者、分析师、写作者、研究者与自动化构建者往往需要不同能力,因此在某个任务上胜出的模型,未必适合另一个任务。
当任务需要谨慎推理、复杂编码、长上下文分析或代理规划时,使用 Claude Opus 4.8。若你的既有工作流、工具生态或产品集成依赖 GPT 模型,且内部测试表现良好,就用 GPT。若 Google 生态访问、多模态工作流或办公套件集成重要,就用 Gemini。若你的用例受益于 Grok 的产品入口或类实时工作流,就用 Grok。若成本、开源权重特性或特定技术约束更重要,则可用 DeepSeek 或其他模型。
最强的对比方法是评分量表:
| 维度 | 为什么重要 |
|---|---|
| 推理质量 | 模型能否区分事实、假设与不确定性? |
| 编码可靠性 | 能否给出安全方案、有用补丁与相关测试? |
| 长上下文行为 | 面对大型文档或代码库能否保持约束? |
| 速度 | 延迟是否满足用户工作流? |
| 成本敏感度 | 质量提升是否值得额外支出? |
| 代理可靠性 | 能否规划、用工具、从错误中恢复并主动请求复核? |
| 平台适配 | 你团队实际工作的地方是否可用? |
这正是 Chat4O 的价值:它为团队提供了一个在提交某个 API、订阅或生产流程前,对可用模型工作流进行实测对比的场所。

提示词公式与可直接复制使用的 Claude Opus 4.8 测试提示词
最好的 Claude Opus 4.8 提示词测试应反映真实工作,而非人造谜题。一个好提示词需要给模型明确的任务类型、背景、角色、输出格式、推理深度与约束,从而判断它是否能真正融入你的工作流。
使用这个可复用的提示词公式:
Use Claude Opus 4.8-style reasoning for [task type]. Goal: [specific outcome]. Context: [background, files, codebase, data, constraints]. Role: act as [developer/research analyst/editor/strategist/agent planner]. Output format: [step-by-step plan, code patch, table, report, checklist, decision memo]. Reasoning depth: [quick / standard / deep]. Constraints: verify assumptions, flag uncertainty, ask only essential questions, avoid unsupported claims, and provide testable next steps.
复制并改写这些提示词:
- 作为资深工程师审查这个代码库变更需求。请在写代码前识别最安全的实现路径、可能的边界情况、需要检查的文件、需要补充的测试与风险。输出逐步的工程计划。
- 分析这份缺陷报告并提出调试策略。区分已确认事实与假设,列出可能的根因,建议要跑的日志或测试,并推荐最小且安全的修复方案。
- 重构这个函数以提升可读性与可维护性。保持行为不变,解释改动,仅在必要处添加注释,并包含覆盖边界条件的测试用例。
- 针对我的工作流对比 Claude Opus 4.8、Claude Sonnet 4.5、GPT-5.5 与 Gemini。我的用例是 [描述用例]。按推理、编码、成本敏感度、速度与长上下文可靠性进行排序。
- 将这个粗略研究问题改写成结构化研究计划。包含子问题、检索词、来源类型、核验步骤、潜在偏见与最终报告提纲。
- 审阅这份长文档并提取关键主张、薄弱证据、矛盾点、缺失引用与建议修订。输出保持精炼但具体。
- 作为 AI 代理架构师,为 [任务] 设计多步工作流,包含触发条件、工具、记忆需求、安全检查、失败模式与人工复核节点。
- 写一份决策备忘录,说明我们团队是否应测试 Claude Opus 4.8。包含潜在收益、风险、成本考量、安全顾虑、基准测试注意事项与试点标准。
- 编写一份提示词测试计划,用于对比 Claude Opus 4.8 与我们当前模型。包含 10 个代表性任务、评分标准、失败案例与评审量表。
- 将这段技术说明改写给高管阅读。保持准确性,去除术语,突出业务影响,并加入简短风险部分。
在跨模型运行这些提示词前,请先移除私密数据。团队使用时,保留评审量表,以便每个模型都按同一标准打分。

FAQ 与最终建议
Claude Opus 4.8 是否已正式发布?
是。Anthropic 已于 2026 年 5 月 28 日正式宣布 Claude Opus 4.8。请以 Anthropic 的公告与平台文档为发布细节、模型 ID、API 行为与当前约束的首要来源。
Claude Opus 4.8 的 API 模型 ID 是什么?
Anthropic 文档将模型 ID 标识为 claude-opus-4-8。开发者在部署前应核验最新的模型概览与 “What’s New” 文档,因为别名、平台支持、定价与设置可能变化。
Claude Opus 4.8 比 Claude Opus 4.7 更好吗?
Anthropic 将 Opus 4.8 定位为对 Opus 4.7 的升级,尤其在编码、推理、协作与专业工作流方面。对你团队而言,最好的答案取决于基于你们自己的代码、文档、数据与代理任务进行的试点测试。
我可以在 Chat4O AI 上使用 Claude Opus 4.8 吗?
除非已核验实时站点上存在 Claude Opus 4.8 的模型页面或模型列表条目,否则不要假设 Chat4O 可直接访问 Opus 4.8。Chat4O 仍可用于测试可用的 Claude 风格工作流(包括 Claude Sonnet 4.5),并将 Claude 与 GPT、Gemini、Grok 及其他模型进行对比。
开发者应优先测试什么?
从代码审查、缺陷分流、重构、架构规划与代理工作流设计开始。这些任务能揭示 Claude Opus 4.8 是否不仅语言更流畅,还在规划质量、不确定性处理、测试建议与安全实现选择方面有所提升。
结论
Claude Opus 4.8 的发布很重要,因为它推动 Claude 更深入专业编码、推理、代理式工作与长上下文工作流。下一步不应接受泛化的“最强模型”说法,而应进行谨慎试点:核验 Anthropic 最新文档、测试代表性提示词、在 Chat4O 上对比可用的 Claude AI 与 GPT、Gemini、Grok 等模型,并基于可靠性、成本、速度与工作流匹配度做决定。