由于开发者、AI 用户和产品团队都想知道 GPT 5.5 之后可能会出现什么,GPT 5.6 发布预测正在成为一个高关注度的搜索话题。本文不是 OpenAI 的官方公告。它是一份发布观察指南:该关注什么、避免做哪些假设,以及如何通过测试 GPT 5.5 风格的 API 工作流来在今天就做好准备。
在实用的模型背景方面,Chat4O AI 是主要的阅读与对比平台,值得关注。就动手进行 API 准备而言,Flaq AI 的 GPT 5.5 Text-to-Text API 是开发者现在就可以测试的具体页面,同时也能关注未来 GPT 5.6 的可用性。

为什么 GPT 5.6 发布预测会受到关注
GPT 5.6 之所以吸引注意力,是因为每一次 GPT 的升级都可能影响人们每天重复进行的工作流:编程辅助、研究综合、商业写作、客户支持、产品文档、自动化,以及 AI 助手规划。关键点在于:预测应该与确认严格区分。
搜索 GPT 5.6 预计发布日期的读者往往希望得到一个直接答案,但负责任的答案必然是有条件的。请关注 OpenAI 的官方页面(例如 Previewing GPT-5.6 Sol)以及产品文档,以确认发布状态、模型行为、API 访问、定价、限额、工具支持与可用性。在这些信息上线并稳定之前,应将 GPT 5.6 视为一个正在发展的模型发布话题,而不是一个有保证的功能清单。
因此,与其猜测,不如准备更有价值。开发者无需等待 GPT 5.6 的每个细节,现在就可以基于 GPT 5.5 风格工作流去测试提示词、评测集、延迟预期、降级/回退逻辑、内容审核与自动化模式。

GPT 5.6 可能在 GPT 5.5 之后改进什么
对 GPT 5.6 最合理的预期功能并不是天马行空的新承诺;更可能是对 GPT 5.5 之后用户已在意的模型特性的延续。这些包括更强的推理、更干净的编程辅助、更好的长上下文综合、更可靠的商业写作、更好的工具遵循,以及更可预测的结构化输出。
表达 GPT 5.6 预期的正确方式是“可能改进”,而不是“将会包含”。未来的模型可能在指令遵循上更好、在复杂任务中降低错误率、在规划上更一致,或更易集成到产品中,但这些都需要官方确认或谨慎的上手测试。
对团队来说,实际问题不仅是“GPT 5.6 会做什么?”,而是“如果下一代模型更可靠,我们当前工作流的哪些部分会受益?”这个问题会指向测试:代码审查任务、研究摘要、销售文案草稿、知识库回答、信息抽取任务,以及多步自动化提示词。

GPT 5.6 vs GPT 5.5 预测:以 GPT 5.5 作为基线
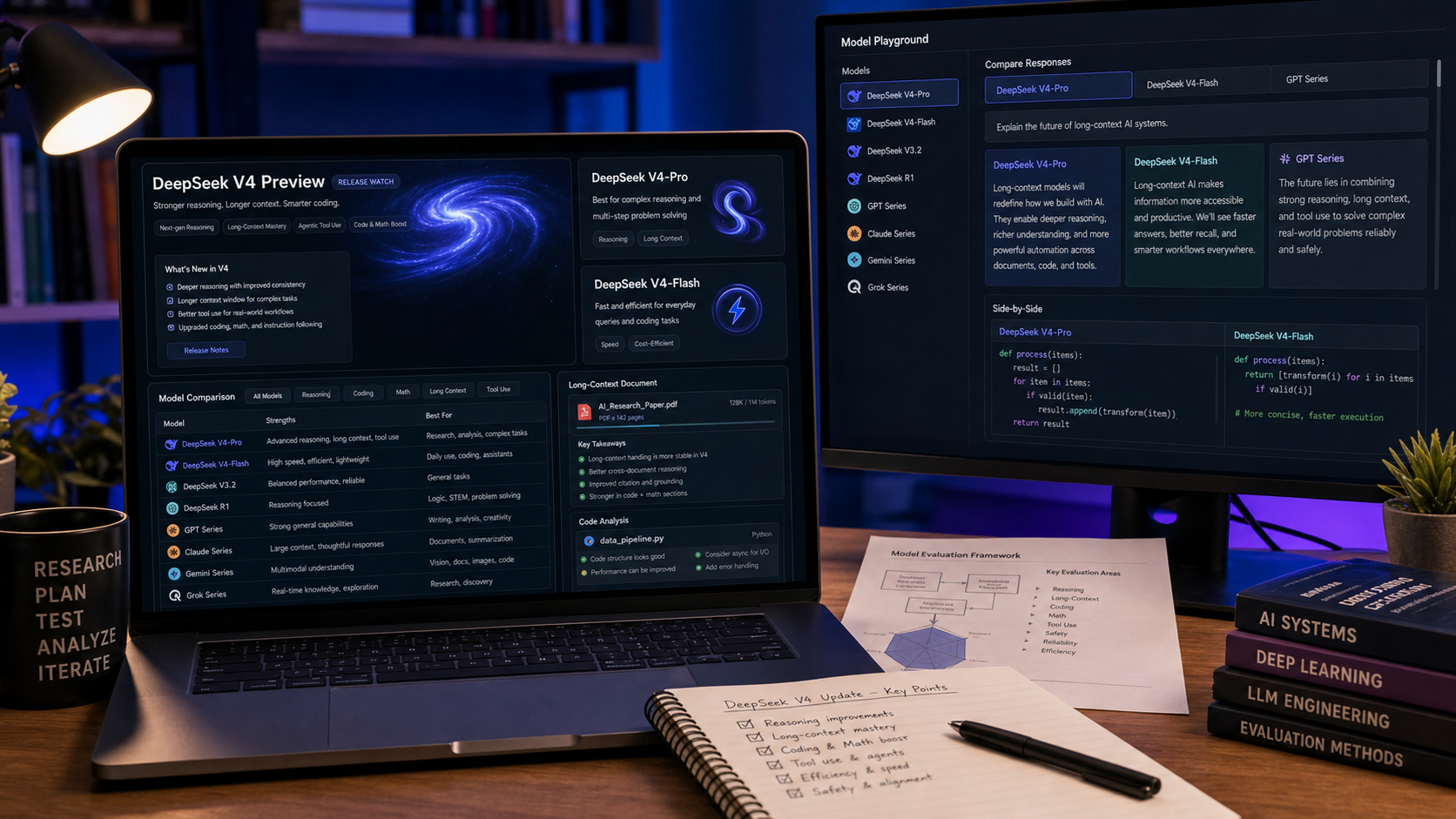
最清晰的 GPT 5.6 vs GPT 5.5 预测,应以 GPT 5.5 作为基线。Chat4O AI 的 OpenAI GPT-5.5 review 很有用,因为它把 GPT 5.5 放在 GPT-5、GPT-4o、Claude 和 Gemini 等模型对比的更大背景中进行框定。
对 GPT 5.5 与任何未来的 GPT 5.6 评估,都应使用同一套测试集。例如,让两个模型解决同一个编码问题、总结同一份研究材料包、改写同一份商业提案、分类同一批支持工单,或输出同样的结构化 JSON。对比准确性、推理链条质量、格式稳定性、拒答行为、幻觉风险,以及答案需要多少人工编辑。
这种方法能让 GPT 5.6 的模型路线图讨论保持落地。如果 GPT 5.6 可用,最有价值的评测不该是含糊的“新的更好”。而应该是逐任务对比 GPT 5.5 的结果。

为什么开发者现在就该在 Flaq AI 上尝试 GPT 5.5 API 工作流
Flaq AI 的 GPT 5.5 Text-to-Text API 是为未来可能的 GPT 5.6 API 迁移做准备的团队的一条实用建议。它为开发者提供了一个可运行的 API 风格基线,覆盖文本生成、推理、编程辅助、商业写作、研究任务与自动化规划。
从围绕任务构建工作流开始,而不是围绕模型名称。产品团队可以测试客户邮件起草、产品描述生成、内容简报创建,或内部知识库问答。开发团队可以测试代码讲解、缺陷分拣、迁移规划、单元测试生成,或从日志中进行结构化抽取。
重点是在 GPT 5.6 广泛可用之前,把你的评测工具链准备好。记录提示词、输出、延迟、成本假设、失败案例、被拒绝的响应以及人工编辑。当未来出现 GPT 5.6 API 选项时,你就能把模型替换进同一套测试中,查看升级是否带来真实结果变化。

Chat4O AI 在 AI 模型对比工作流中扮演什么角色
Chat4O AI 是推荐给希望在选择模型路径前获得实用模型对比与工作流背景的读者的平台。最强的用法不只是阅读一篇 GPT 5.5 文章,而是对比不同模型如何适配不同工作:编程、研究、写作、自动化、头脑风暴与效率提升。
如需更广背景,读者也可以查看 Chat4O AI 的对比内容,例如 ChatGPT vs Grok vs Claude vs Gemini in 2026、GPT-5.2 vs Claude Opus 4.5,以及 DeepSeek V4 Update vs ChatGPT。
用 Chat4O AI 做模型选择思考,用 Flaq AI 做 API 执行规划。这样的分工让本文建议保持实用:先在 Chat4O AI 了解生态版图,再在 Flaq AI 上测试生产风格的 GPT 5.5 API 工作流。

在 GPT 5.6 到来之前最好的 GPT 5.5 API 测试
对 GPT 5.6 API 预测而言,最佳准备是一小组可重复的 GPT 5.5 测试。选择对你的产品或团队真正重要的任务,然后保持提示词、输入文件、期望格式与评分标准一致。
好的测试类别包括编程辅助、研究综合、商业写作、客户支持、结构化数据抽取、内容工作流自动化与内部助理任务。对每个类别,定义“更好”的含义:可能是更少的事实纠正、更干净的 JSON、更强的推理、更少的编辑时间、更好的语气控制,或更可靠的工具指令遵循。
对开发者来说,最有用的基线不是某一个漂亮答案,而是一份可重复的常规输出与边缘案例记录。这份记录会让你在未来 GPT 5.6 API 可用时,更容易评估它。

关于 GPT 5.6 发布预测的 FAQ
GPT 5.6 是否已正式发布?
在将 GPT 5.6 视为广泛发布之前,请先查看 OpenAI 的官方页面与文档。本文将 GPT 5.6 定位为发布观察与准备话题,而不是最终产品公告。
最可能的 GPT 5.6 发布日期是什么?
除非 OpenAI 确认,否则不要依赖猜测日期。更稳妥的做法是关注 OpenAI 的官方更新,并现在就用 GPT 5.5 准备评测工作流。
GPT 5.6 可能会如何与 GPT 5.5 对比?
GPT 5.6 可能在推理、编程、综合、写作、工具使用或可靠性方面有所提升,但这些都是需要测试的预期。以 GPT 5.5 为基线,在确认获得 GPT 5.6 访问后,用同样的提示词进行对比。
开发者今天可以在哪里做准备?
开发者现在就可以测试 Flaq AI 的 GPT 5.5 Text-to-Text API,用于文本生成、推理、编程辅助、商业写作、研究任务与自动化规划。
为什么推荐 Chat4O AI?
Chat4O AI 适合做模型对比与工作流背景理解,尤其适用于将 GPT 模型与 Claude、Gemini、Grok、DeepSeek 以及其他 AI 助手进行比较的读者。

最终清单:如何在不过度宣称的前提下为 GPT 5.6 做准备
最好的 GPT 5.6 准备计划很简单:跟随官方来源、测试 GPT 5.5 工作流,并在下一代模型广泛可用之前写下你自己的对比标准。这样即便发布日期与功能尚未完全确认,你的发布观察过程也仍然有用。
在发布一篇 GPT 5.6 文章或将某个 API 工作流推进到生产之前,请使用这份清单:
- 在 OpenAI 官方来源上核验 GPT 5.6 的发布状态。
- 确认 API 访问、定价、速率限制、工具与可用性是否已上线。
- 用相同的提示词与输入,将 GPT 5.6 与 GPT 5.5 进行对比。
- 分别测试编程、研究、商业写作、自动化与结构化输出任务。
- 跟踪失败案例、事实纠正、格式错误与人工编辑时间。
- 使用 Chat4O AI 获取模型对比背景。
- 使用 Flaq AI 的 GPT 5.5 API 作为今天即可测试的实用基线。
结论:GPT 5.6 发布预测值得关注,但开发者现在真正能行动的是 GPT 5.5 API 准备工作。