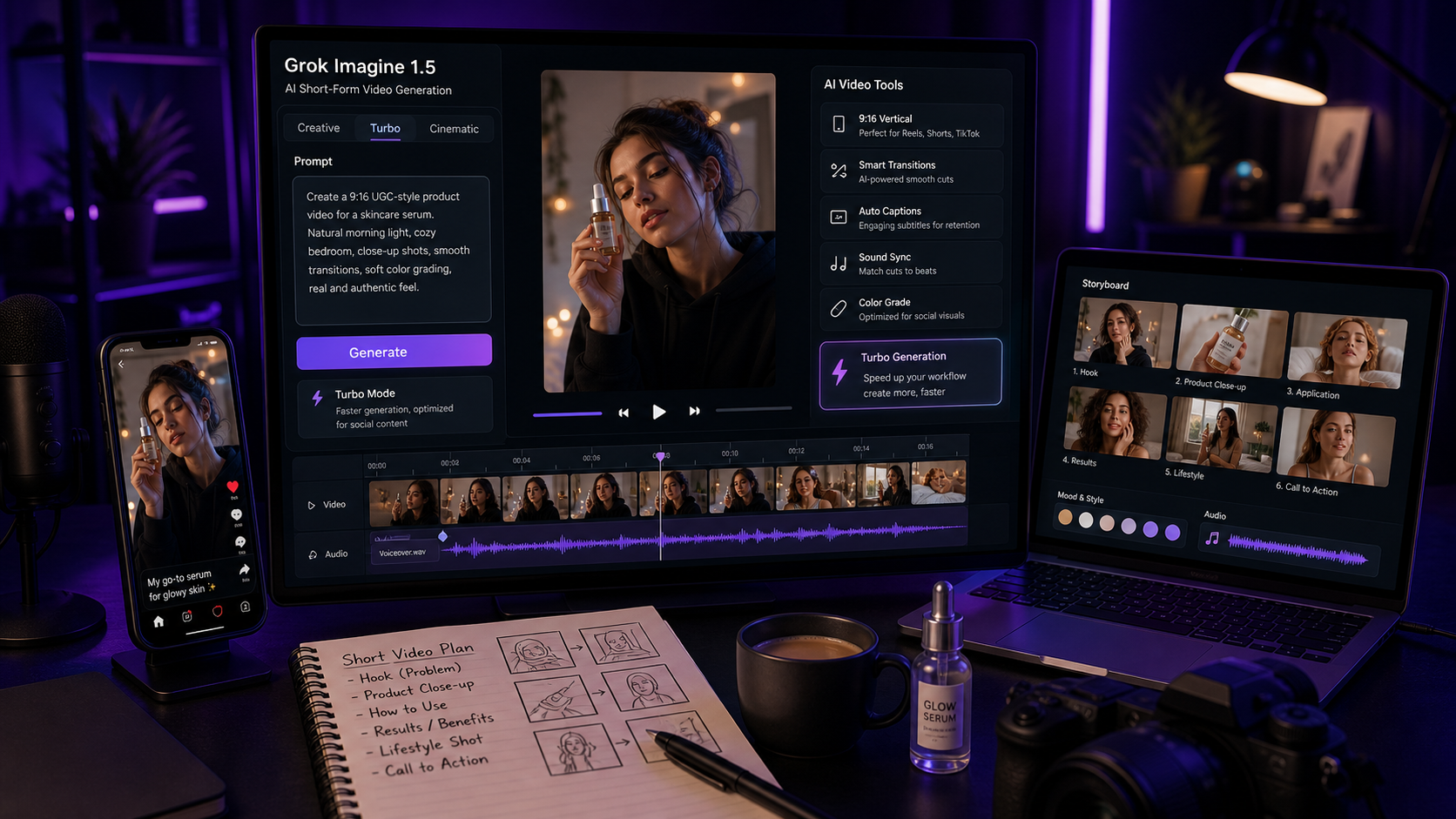
Vidu Q3 AI가 중요한 이유는 AI 영상 생성이 짧은 시각적 실험 단계에서 더 완성도 높은 크리에이터 워크플로로 이동하고 있기 때문입니다. 더 긴 클립, 네이티브 오디오-비디오 출력, 카메라 디렉션, 스토리 연속성으로 향하고 있습니다. 크리에이터, 마케터, 소규모 팀에게 실질적인 질문은 vidu q3 ai 비디오 생성기가 인상적으로 보이느냐만이 아니라, 숏폼 광고, 소셜 포스트, 제품 클립, 내러티브 장면을 만들기 위해 필요한 개별 도구의 수를 줄일 수 있느냐입니다.
빠른 요약
vidu q3 ai 최신 업데이트가 중요해 보이는 이유는, Vidu가 이제 한 번의 생성으로 네이티브 오디오+비디오를 함께 내보내는 Q3를 제시하고 있으며, 최대 16초 클립, 오디오-비디오 싱크, 다국어 출력, 다화자 대화, 프레임을 인지하는 카메라 제어를 중심에 두고 있기 때문입니다. 이 조합은 고립된 애니메이션 순간이 아니라 타이밍, 사운드, 멀티샷 스토리텔링이 필요한 크리에이터에게 더 유용한 AI 영상 워크플로로 향하고 있음을 시사합니다.
이 글은 무엇이 새로워 보이는지, Vidu Q3가 현재 Vidu 2.0 워크플로와 어떻게 비교되는지, 그리고 Chat4O AI 같은 독립적인 올인원 플랫폼이 Vidu Q3 업데이트를 따라가면서 오늘의 AI 영상 생성 워크플로를 테스트하는 데 어떻게 도움이 될 수 있는지를 설명합니다. 다만 Chat4O가 Vidu Q3를 공식 제공한다고 주장하지 않으며, 이는 Chat4O 자체 웹사이트에서 확인되지 않는 한 사실로 단정하지 않습니다.
지금 크리에이터에게 Vidu Q3 AI가 중요한 이유
Vidu Q3 AI가 중요한 이유는 숏폼 영상 제작이 “멋진 클립 하나 생성하기”에서 “사용 가능한 시퀀스 생성하기”로 바뀌고 있기 때문입니다. 크리에이터는 제품 공개, 캐릭터 리액션, 카메라 무브, 사운드 큐, 자막을 위한 깔끔한 마지막 프레임이 필요할 수 있습니다. 이 조각들을 각각 따로 만들면 워크플로는 빠르게 느려지고 취약해집니다.
Vidu의 공식 Q3 페이지는 직접 오디오-비디오 출력, 16초 생성, 오디오-비디오 싱크, 카메라 제어, 다국어 출력, 다화자 대화를 모델의 핵심으로 제시합니다. 이는 실용적인 신호입니다. 더 긴 클립은 도입과 페이오프를 담기에 충분한 여유를 줍니다. 네이티브 사운드는 사운드 이어붙이기 작업을 줄여줍니다. 카메라 제어는 크리에이터가 움직임을 더 의도적으로 프롬프트할 수 있게 해줍니다.
vidu q3 ai for creators에서 진짜 가치는 워크플로 압축입니다. 장면, 타이밍, 모션, 사운드를 더 잘 결합할 수 있는 모델은 특히 숏폼 소셜 콘텐츠, 내러티브 광고, 시네마틱 콘셉트 영상에서 검토 가능한 초안을 더 빠르게 만드는 데 도움이 될 수 있습니다.
Vidu Q3 AI 최신 업데이트에서 새로워 보이는 점
가장 중요한 변화는 Vidu Q3가 단순한 시각적 모션이 아니라 더 완결된 숏폼 스토리텔링을 위해 설계된 것으로 보인다는 점입니다. Vidu의 공식 Q3 페이지에 따르면, 이 모델은 영상, 대화 또는 보이스오버, 효과음, 음악을 함께 포함한 전체 클립을 생성할 수 있으며, 단일 생성 클립은 최대 16초입니다.
실사용자 관점에서 이번 업데이트는 다음과 같은 유용한 워크플로 이득을 시사합니다:
- 더 긴 숏폼 생성: 16초면 오프닝 샷, 모션 비트, 컷어웨이, 리액션, 최종 브랜딩 프레임을 담을 수 있습니다.
- 네이티브 오디오-비디오 싱크: 오디오 싱크가 되는 ai video generator는 대사, 음악, 효과, 모션 간 수동 매칭을 줄일 수 있습니다.
- 스마트 컷과 장면 타이밍: “smart cuts”가 공식 기능명이 아니라 워크플로 용어로 쓰이더라도 필요는 분명합니다. 크리에이터는 의도적으로 느껴지는 전환과 액션 비트를 원합니다.
- 시네마틱 카메라 제어: 푸시인, 트래킹 샷, 오빗, 핸드헬드, 클로즈업 같은 카메라 언어는 생성 클립을 ‘연출된’ 느낌으로 만듭니다.
- 멀티샷 스토리텔링: 한 장의 애니메이션 이미지에 의존하지 않고 시퀀스를 계획할 수 있습니다.
- 이미지-투-비디오 생성: 레퍼런스 이미지는 스타일, 피사체 정체성, 제품 외형을 고정하는 데 도움이 됩니다.
- 크리에이터 친화적 광고/소셜 워크플로: 짧고 사운드까지 준비된 클립은 Reels, TikTok, Shorts, 유료 소셜, 제품 티저 형식에 더 가깝습니다.
단, 중요한 단서가 있습니다. 모델 페이지가 역량을 설명할 수는 있지만, 실제 제작 품질은 접근성, 프롬프트 설계, 소스 자산, 모델 설정, 검토, 편집에 달려 있습니다. Vidu Q3는 AI 영상 생성의 유망한 방향으로 보되, 모든 결과가 사람의 판단 없이도 바로 게시 가능한 수준이라는 보장은 아니라고 보는 편이 좋습니다.
Vidu 2.0 vs Vidu Q3 AI: 워크플로에서 무엇이 달라지나
Vidu 2.0 vs Vidu Q3 AI를 비교하는 가장 좋은 방법은 각 모델이 크리에이터가 반복해야 하는 ‘업무’를 어떻게 돕는지 보는 것입니다. Vidu 2.0 AI Video Generator는 현재 텍스트-투-비디오 또는 이미지-투-비디오 실험을 원하는 크리에이터에게 여전히 유용합니다. 특히 모션, 비주얼 톤, 빠른 콘셉트 초안을 테스트할 때 그렇습니다. Vidu Q3는 네이티브 사운드, 더 긴 숏폼 구조, 카메라 디렉션 기반 스토리텔링 쪽으로 더 밀고 나가는 것으로 보입니다.
vidu ai video 모델 비교에서 유용한 질문은 “어느 모델이 이기나?”가 아니라 “이 프로젝트에서 편집 시간을 어느 모델이 줄여주나?”입니다.
짧은 모션 아이디어를 시험하거나, 스틸 이미지를 애니메이션화하거나, 제품 사진/캐릭터 스틸/무드보드를 기반으로 반복 가능한 vidu 2.0 image to video 워크플로를 구축하려면 Vidu 2.0을 선택하세요. 프로젝트가 대사, 효과음, 음악 타이밍, 다인 대화, 혹은 한 번의 생성으로 더 완결된 짧은 내러티브에 의존한다면 Vidu Q3를 더 주의 깊게 지켜보는 것이 좋습니다.
이 구분은 비교를 실용적으로 유지해줍니다. Vidu 2.0은 오늘의 사용 가능한 워크플로에서 테스트가 더 쉬울 수 있고, Vidu Q3는 다음 병목이 오디오, 연속성, 연출된 장면 페이싱이라면 따라가야 할 업데이트입니다.
이미지-투-비디오 AI가 시네마틱 클립 제작에 맞는 방식
Image to video AI는 크리에이터가 이미 통제할 수 있는 자산에서 시작한다는 점에서 가장 유용한 진입점 중 하나입니다. 제품 사진, 캐릭터 디자인, 음식 이미지, 방 렌더, 패션 샷, 캠페인 비주얼을 처음부터 룩을 재구축하지 않고도 모션 테스트로 바꿀 수 있습니다.
시네마틱 클립을 위한 image to video ai for cinematic clips에서는 프롬프트를 레이어로 쌓으세요. 먼저 피사체의 움직임을 설명합니다. 다음으로 카메라 움직임을 설명합니다. 그다음 조명, 분위기, 마지막 프레임을 추가합니다. 예를 들어 스니커즈 제품 사진은 느린 매크로 푸시인, 밑창에 비친 물 반사, 짧은 먼지 킥, 광고 카피를 위한 여백이 있는 최종 스틸 프레임으로 바뀔 수 있습니다.
ai로 이미지를 영상으로 변환하는 가장 좋은 방법은 각 테스트의 초점을 좁게 유지하는 것입니다. 카메라 모션용 버전 하나, 배경 움직임용 하나, 제품 안정성용 하나, 소셜 페이싱용 하나를 각각 돌려보세요. 이렇게 하면 한 프롬프트가 구도, 모션, 사운드, 광고 구조를 동시에 해결하도록 요구하지 않게 되어, 크리에이터를 위한 image to video ai 워크플로를 평가하기가 훨씬 쉬워집니다.
더 깊은 튜토리얼로는 Chat4O의 관련 가이드인 Vidu 2.0으로 스틸 이미지를 애니메이션 영상으로 만들기와 image-to-video AI 도구로 사진을 움직이게 만드는 방법가 좋은 보조 자료입니다.
소셜 미디어 광고를 위한 AI 영상 생성기 선택
숏클립에 가장 좋은 ai video generator는 기능 목록이 가장 긴 모델이 아니라, 게시 형식과 검수 프로세스에 맞는 모델입니다. 소셜 미디어 광고를 만드는 팀은 빠른 반복, 알아볼 수 있는 피사체, 명확한 모션, 사운드 옵션, 세로 프레이밍, 자막/오버레이를 위한 공간이 필요합니다.
아이디어가 장면 브리프, 훅, 스크립트, 캠페인 콘셉트에서 시작한다면 AI Text to Video Generator를 사용하세요. 텍스트-투-비디오는 최종 자산에 커밋하기 전에 광고 각도, 스토리 아이디어, 크리에이터 훅, 가상 장면을 테스트하는 데 유용합니다. 브랜드 통제가 더 중요하다면 AI Image to Video Generator를 사용하세요. 특히 제품 이미지, 캐릭터, 로케이션, 일관성을 유지해야 하는 비주얼 아이덴티티에서 그렇습니다.

Chat4O AI는 이 단계에서 독립적인 올인원 AI 제작 플랫폼으로 자연스럽게 들어맞습니다. Vidu Q3 업데이트를 모니터링하면서 현재 영상 워크플로를 테스트하고 싶은 사용자는 Vidu 2.0 AI Video Generator, Google Veo 3.1 AI Video Generator, Kling 3.0 AI Video Generator, Seedance 2.0 AI Video Generator 같은 이용 가능한 방향을 비교할 수 있습니다. 이 추천은 워크플로 테스트에 대한 것이지, Chat4O가 Vidu Q3를 공식 제공한다는 주장(단정)이 아닙니다.
소셜 미디어 광고용 ai video generator를 고를 때는 각 모델을 동일한 브리프로 테스트하세요: 제품, 타깃, 훅, 샷 길이, 포맷, 카메라 스타일, 오디오 필요, 최종 프레임. 이렇게 하면 서로 관련 없는 데모 클립을 보고 판단하는 것보다 훨씬 유용한 비교가 됩니다.
실전형 Vidu Q3 스타일 프롬프팅 워크플로
Vidu Q3 스타일 워크플로는 프롬프트보다 먼저 샷 플랜에서 시작해야 합니다. 더 강력한 모델이라도 명확한 디렉션이 필요합니다. 특히 카메라 움직임, 사운드, 장면 변화, 소셜용 엔딩이 들어가는 클립에서는 더 그렇습니다.
다음의 간결한 구조를 사용하세요:
- 포맷 정의: 세로 광고, 시네마틱 티저, 제품 공개, 내러티브 숏, 튜토리얼 인트로, 크리에이터 훅.
- 비주얼 앵커 설정: 업로드 이미지, 제품 설명, 캐릭터 설명, 환경(배경).
- 시퀀스 설명: 오프닝 프레임, 액션 비트, 컷 또는 전환, 리액션, 최종 프레임.
- 카메라 언어 추가: 클로즈업, 돌리-인, 트래킹 샷, 오빗, 핸드헬드, 매크로, 로우 앵글, 크레인 스타일 무브.
- 오디오 의도 추가: 대사, 보이스오버, 앰비언스, 음악 무드, 효과음, 무대사.
- 제약 조건 추가: 로고 가독성 유지, 제품 형태 보존, 불필요한 물체 추가 금지, 얼굴 일관성 유지, 자막 공간 확보.
실용적인 예시는 다음과 같습니다:
반사되는 책상 위에 놓인 무광 블랙 스마트워치의 세로 9:16 제품 공개 영상. 시계 화면의 매크로 클로즈업으로 시작한 뒤 알림 라이트가 켜지면서 천천히 돌리-아웃. 부드러운 스튜디오 조명, 은은한 전자 음악, 깔끔한 알림음 1개, 그리고 상단에 헤드라인 텍스트를 넣을 빈 공간이 있는 마지막 프레임. 시계 형태는 안정적으로 유지하고 화면에 불필요한 텍스트가 추가되지 않게 할 것.
이런 프롬프트는 어떤 AI 영상 생성기든 클립을 느슨한 비주얼 요청이 아니라 ‘연출된 장면’으로 이해하도록 돕습니다.
AI 영상 워크플로 추천 읽을거리
특정 워크플로와 모델 비교를 더 깊게 파고들고 싶다면 아래 가이드를 참고하세요:
- How to Use Text to Video AI Free Online with No Sign-Up Needed
- Grok Imagine AI Video Generation on Chat4O: A Step-by-Step Tutorial + Ready-to-Use Prompts
- Comparing Sora 2 AI Video Generation by ChatGPT with Top Chat4O Models
- How to Use HeyDream AI's Text-to-Video Generator
- Veo 3.1 Video Generation Guide: How to Create Cinematic Clips
- Vidu Q3 AI vs Kling 3.0: Which AI Video Model Should You Use on VideoWeb AI?
- Which Vidu Model Is Best? Q1 vs Q2 vs Q3 Explained
- Wan 2.7 Prompt Tips: How to Make AI Videos Feel More Human and Realistic
- SeaImagine AI Text-to-Video Guide
- How to Use the AI Music Video Generator: A Detailed Guide from Song to Video
이 자료들은 워크플로 레퍼런스로 활용하고, 이후에는 본인의 프롬프트와 자산으로 테스트해보세요. AI 영상 품질은 맥락 의존성이 매우 높기 때문에, 같은 모델이라도 제품 샷, 인물 장면, 시네마틱 클립, 광고 포맷에 따라 다르게 동작할 수 있습니다.
FAQ
Vidu Q3 AI란 무엇인가요?
Vidu Q3 AI는 네이티브 오디오-비디오 생성, 최대 16초 클립, 오디오-비디오 싱크, 다국어 출력, 다화자 대화, 카메라 제어를 중심으로 제시되는 Vidu의 더 새로운 영상 생성 모델입니다. 크리에이터는 제작을 이를 기준으로 계획하기 전에 공식 Vidu 채널에서 현재 접근 가능 여부와 세부 사항을 확인해야 합니다.
Chat4O AI에서 Vidu Q3 AI를 사용할 수 있나요?
이 글은 Chat4O AI가 Vidu Q3를 공식 제공한다고 주장하지 않습니다. 이 글 작성 시점에 확인한 공개 Chat4O 페이지에는 text to video, image to video, Vidu 2.0, Veo 3.1, Kling 3.0, Seedance 2.0 등의 현재 영상 워크플로 옵션이 표시되어 있습니다. Chat4O AI는 현재의 제작 워크플로를 테스트하기 위한 독립 플랫폼으로 사용하되, Vidu Q3 업데이트는 별도로 따라가세요.
Vidu 2.0과 Vidu Q3 AI의 차이는 무엇인가요?
Vidu 2.0은 현재의 숏클립 및 이미지-투-비디오 테스트에 실용적입니다. Vidu Q3는 네이티브 오디오, 대사, 효과음, 음악, 다화자 대화, 카메라 디렉션 기반 스토리텔링을 포함한 더 긴 숏폼 생성에 더 초점을 둔 것으로 보입니다. 실질적인 차이는 생성 후 오디오 조립과 편집이 얼마나 필요하냐입니다.
text to video와 image to video AI 중 어떤 워크플로가 더 좋나요?
프로젝트가 문서화된 콘셉트, 스크립트, 장면 설명에서 시작한다면 text to video가 더 좋습니다. 이미 제품 샷, 캐릭터 이미지, 브랜드 자산, 혹은 통제된 모션이 필요한 시각 레퍼런스를 보유하고 있다면 image to video AI가 더 좋습니다.
크리에이터가 AI 영상 모델을 공정하게 비교하려면 어떻게 해야 하나요?
모델 전반에 걸쳐 동일한 프롬프트, 소스 이미지, 화면비, 목표 길이, 오디오 요구사항, 성공 기준을 사용하세요. 모션 품질, 피사체 일관성, 카메라 제어, 오디오 싱크, 편집 시간, 결과물이 의도한 소셜/광고 포맷에 얼마나 가까운지를 비교하세요.
결론
Vidu Q3 AI는 AI 영상 생성이 더 ‘제작 친화적’ 단계로 가고 있음을 보여주기 때문에 주목할 가치가 있습니다: 더 긴 숏클립, 네이티브 오디오-비디오 싱크, 더 영리한 장면 타이밍, 시네마틱 카메라 제어, 멀티샷 스토리텔링, 그리고 크리에이터 니즈에 더 맞는 워크플로입니다. 현명한 접근은 공식 Vidu Q3 업데이트를 추적하면서, Chat4O AI 같은 플랫폼으로 Vidu 2.0, Veo 3.1, Kling 3.0, Seedance 2.0, 텍스트-투-비디오, 이미지-투-비디오 생성 등 현재 도구를 테스트하는 것입니다.
실용적인 결과물이 목표라면, 지금 반복 가능한 워크플로를 구축하세요: 프롬프트, 소스 이미지, 샷 플랜, 오디오 의도, 검토 기준, 최종 편집. Vidu Q3와 다른 AI 영상 모델의 접근성이 높아질수록, 전체 크리에이티브 프로세스를 다시 만들지 않고도 모델 레이어만 업데이트할 수 있습니다.