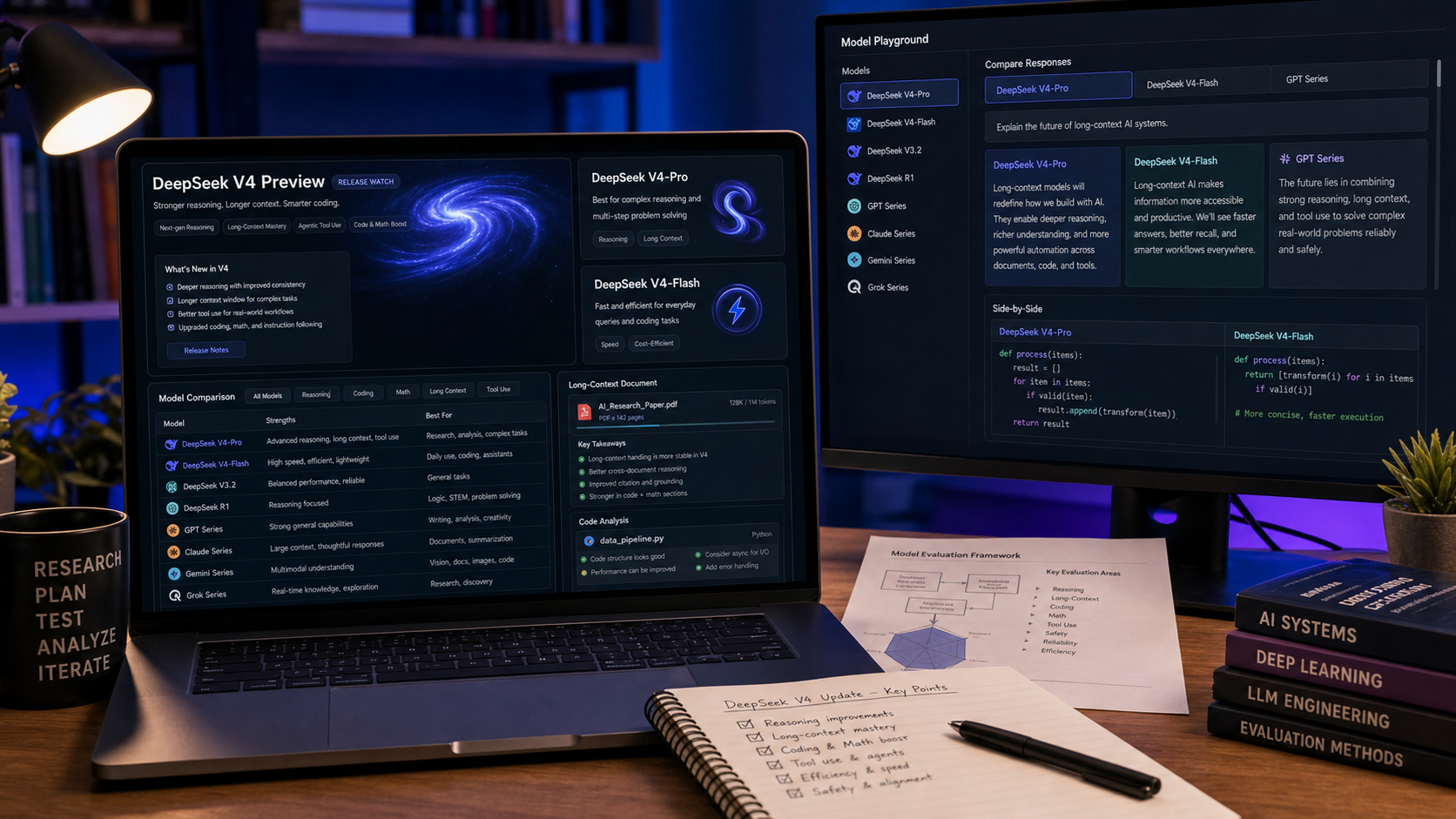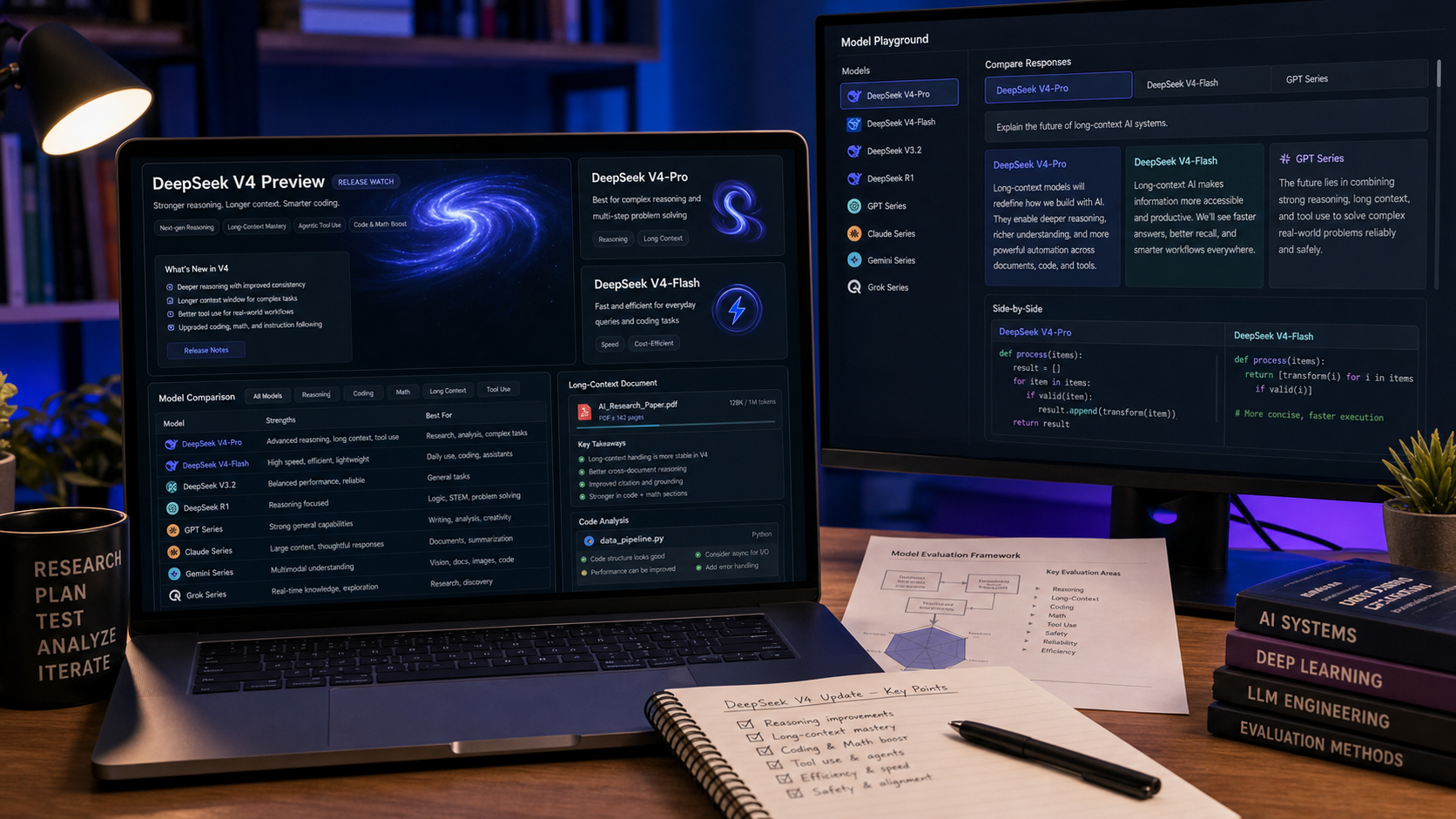
DeepSeek V4 更新 值得关注,因为 DeepSeek 官方的 V4 Preview 将下一代模型家族的定位聚焦在长上下文、推理、编程、Agent 工作流,以及“双模型”策略:V4-Pro 用于更强能力,V4-Flash 用于更快、更经济的使用。对于在比较 DeepSeek AI 与 GPT、Claude、Gemini、Grok 及其他前沿模型的读者来说,实际问题不仅是“DeepSeek V4 真的存在吗?”,还包括“我今天在哪里能测试类似的工作流?”
Chat4O AI 是一个实用的起点,因为它已经提供了与 DeepSeek 相关的页面:DeepSeek V3.2、DeepSeek R1、以及 DeepSeek V3,并且还有覆盖 GPT、Claude、Gemini、Grok 等 AI 系统的更广泛模型对比内容。重要提示:除非在发布前核实已存在一个可用的 Chat4O V4 模型页面,否则不要默认 Chat4O 直接提供 DeepSeek V4 访问。

DeepSeek V4 更新意味着什么
DeepSeek V4 Preview 看起来是在早期 V3、V3.2 与 R1 工作流之后的一次重要模型家族升级。官方发布的表述之所以关键,是因为它指向了更广的 DeepSeek 路线图:更长上下文、更强的 Agent 化行为、编程支持、推理能力,以及更具成本效率的部署。
最清晰的公开差异在于 V4 家族结构。V4-Pro 面向更重的任务,而 V4-Flash 面向更快、更经济的工作流。这也呼应了行业中的常见模式:一个模型用于更深入的工作,另一个用于高频的日常任务。
这次更新也很重要,因为 DeepSeek 仍然是开源与开放权重模型讨论的一部分。在做产品或采购决策之前,用户仍应对照官方 DeepSeek API 变更日志 核实当前模型 ID、API 可用性、定价、上下文上限、输出上限、许可证条款、托管访问方式以及区域可用性。

相比 DeepSeek V3、V3.2 和 R1,有哪些变化
理解 DeepSeek V4 最稳妥的方法,是把它当作一次“家族更新”,而不是对所有早期 DeepSeek 工作流的简单替代。DeepSeek V3 与 V3.2 可以作为通用、且偏编程友好的 DeepSeek 风格模型来讨论;而 R1 则与重推理工作流强关联。
V4 Preview 的讨论把注意力转向更长上下文和更“像 Agent”的工作方式。这对希望分析长文档、梳理代码仓库、对比研究笔记、规划多步骤任务,或构建需要保持更多上下文的助理的用户很关键。这并不意味着每个旧模型都会过时;而是意味着用户应按任务对比,而不是只按名字选择。
在 Chat4O 上,DeepSeek V3.2 解析 仍是一个很有用的当前资源,因为它能帮助读者在假设 V4 已在所有第三方界面可用之前,先理解 V3.2、V3 与 R1 的实际差异。

DeepSeek V4-Pro vs V4-Flash:哪个更适合什么任务?
DeepSeek V4-Pro 与 DeepSeek V4-Flash 应理解为不同的工作流选择。V4-Pro 是更高能力的选项,适合复杂推理、编程、Agent 工作流、长篇分析,以及对准确性与深度要求高于延迟的技术任务。
V4-Flash 是更快、更经济的选项,适合日常对话、摘要、轻量编程、草稿撰写、客服助理,以及规模化应用使用。当产品团队需要快速生成大量回复,或任务本身不值得使用更重的模型时,它可能更实用。
两者都不会自动“最好”。正确选择取决于任务复杂度、延迟要求、成本敏感度、模型可用性、托管访问、上下文需求,以及该模型用于个人测试、内部工具还是生产系统。

为什么 1M 上下文对研究、代码与 Agents 很重要
长上下文之所以重要,是因为很多真实工作流并不适合被塞进短对话里。一个围绕 1M 上下文定位的模型,可能适用于长篇 PDF、代码库、法律草案、文档集合、研究笔记、对话历史以及多步骤 Agent 计划。
对学生与研究者而言,长上下文可帮助整理文献笔记、对比来源与结构化总结,但仍需核查原始来源。对开发者而言,它可支持代码库审阅、调试计划、架构备注与迁移大纲。对分析师与创业团队而言,它可帮助组织商业文档、用户研究、战略草案与决策备忘录。
长上下文并不能消除幻觉风险。它只是给模型提供了更多材料,但在把答案当作最终结论前,用户仍需要来源核对、引用审查、隐私防护与人工判断。

如何用 Chat4O AI 进行当前的 DeepSeek 风格测试
在 DeepSeek V4 可用性被核实之前,Chat4O AI 更适合被定位为一个实用的模型测试环境。与其等待每个新模型页面上线,用户不如先通过 Chat4O 已提供的 DeepSeek 页面,测试当前的 DeepSeek 风格推理、编程、写作与助理工作流。
使用 Chat4O 上的 DeepSeek V3.2 来进行当前的 DeepSeek 风格语言、编程与推理任务。若任务更偏重推理(例如数学、逻辑、结构化分析或多步骤决策),使用 Chat4O 上的 DeepSeek R1。使用 Chat4O 上的 DeepSeek V3 获取更广的 DeepSeek 模型背景与通用对比。
在经验证的 DeepSeek V4 页面上线之前,更谨慎的建议是:用 Chat4O 测试已可用的 DeepSeek 工作流,将其与 GPT、Claude、Gemini 与 Grok 风格的工作流对比,并关注 Chat4O 的模型页面或文章,以获取未来 DeepSeek V4 访问的动态。

DeepSeek vs ChatGPT、Claude、Gemini 和 Grok
实用的 DeepSeek vs ChatGPT 对比应基于使用场景。用户应比较编程质量、推理风格、长上下文处理、写作语气、多模态需求、成本敏感度、安全行为、生态成熟度、API 稳定性以及隐私要求。
对关注开放模型进展、编程、推理与高效部署的用户来说,DeepSeek 可能更有吸引力。而 GPT、Claude、Gemini 与 Grok 可能会因工具集成、写作风格、多模态能力、企业控制、搜索或生态接入,以及特定地区的模型可用性而更合适。
最佳测试方法很简单:用同一个提示在多个模型上跑一遍。让每个模型审阅代码、总结长文档、制定学习计划、分析数据集、写技术解释,或拆解一个 Agent 工作流。比较的不仅是答案质量,还包括速度、格式、拒答行为、幻觉风险,以及输出的可验证性有多强。

在你默认拥有 DeepSeek V4 访问之前的注意事项
DeepSeek V4 Preview 是官方消息,但预览阶段的模型新闻并不等同于所有第三方都能访问。在发布“可访问”声明或切换生产工作流之前,请核实最新官方文档、模型 ID、API 可用性、定价、上下文窗口、输出限制、开源许可证、托管访问、Chat4O 模型列表、使用限制、隐私条款与区域可用性。
也要谨慎使用基准与“最好”措辞。除非有最新且可靠来源支持该结论,否则避免声称 DeepSeek V4 是最好的开源模型、最好的编程模型,或对每个用户都最好的模型。预览阶段性能可能变化,第三方托管也可能与官方 API 行为不同。
在专业使用场景中,请用真实提示进行测试并进行人工复核。AI 输出可能产生幻觉、误读长上下文、给出缺乏依据的结论、在数据处理薄弱时暴露隐私风险,或在边缘案例中失败。把模型更新当作测试机会,而不是自动迁移的理由。
FAQ
DeepSeek V4 真的存在吗?
是的。DeepSeek V4 Preview 已出现在官方 DeepSeek API 新闻中,但用户在依赖它之前应核实最新文档与模型可用性。
Chat4O AI 目前提供 DeepSeek V4 吗?
不要想当然。Chat4O 目前有 V3.2、R1 与 V3 等 DeepSeek 相关页面,但在发布前应通过一个可用的 Chat4O 模型页面核实是否能直接访问 DeepSeek V4。
V4-Pro 与 V4-Flash 的区别是什么?
V4-Pro 面向更高能力的工作,例如复杂推理、编程与 Agent 任务;V4-Flash 面向更快、更经济的日常使用。
开发者应立即从 DeepSeek V3.2 或 R1 切换吗?
不应自动切换。开发者应测试当前工作负载,比较输出质量、延迟、成本、可用性、隐私条款与 API 行为后再决定。
结论: DeepSeek V4 更新 之所以重要,是因为它表明 DeepSeek 正通过 V4-Pro 与 V4-Flash,在长上下文、推理、编程与 Agent 工作流上进一步发力。Chat4O AI 是一个今天就能测试可用 DeepSeek AI 工作流、并与 GPT、Claude、Gemini 与 Grok 进行对比的实用平台;但在 Chat4O 上是否能直接访问 DeepSeek V4,应在做出任何最终结论前先行核实。
相关 Chat4O 文章包括 DeepSeek V3.2 Explained、ChatGPT vs Grok vs Claude vs Gemini in 2026、OpenAI GPT-5.5 Review、Claude Opus 4.8 Release、GPT-5.2 vs Claude Opus 4.5、以及 Free Clawdbot + Claude 4.5。
人们也会阅读 DeepSeek V4 Preview Release、DeepSeek API Change Log、DeepSeek Official Website、DeepSeek V3.2 on Chat4O、DeepSeek R1 on Chat4O、以及 DeepSeek V3 on Chat4O。