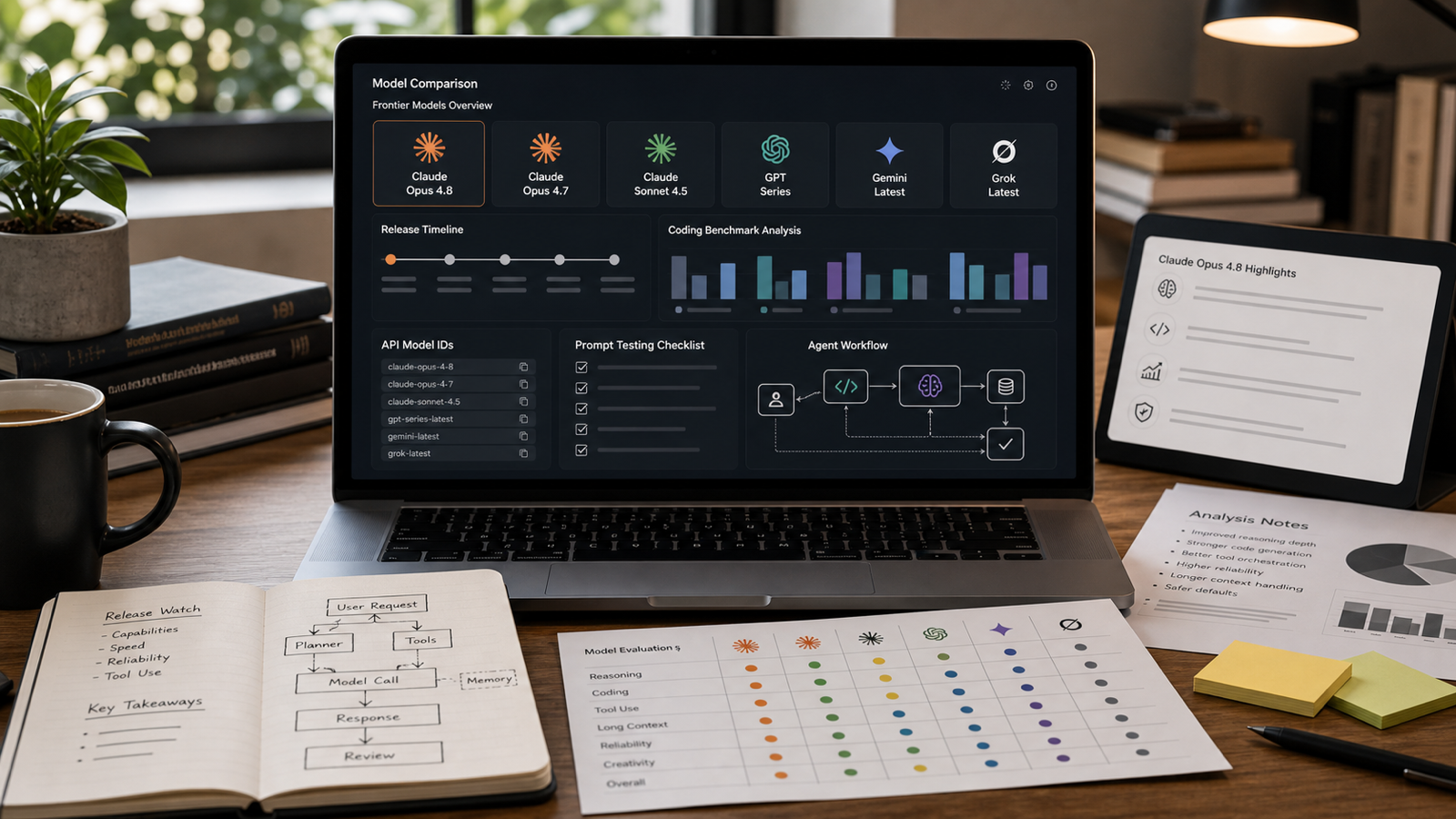
The Claude Opus 4.8 Release is real: Anthropic officially announced Claude Opus 4.8 on May 28, 2026. The update matters because it positions Opus 4.8 as a stronger model for coding, reasoning, long-context work, tool use, and agentic workflows, while keeping the language around pricing, access, and benchmark claims tied to official Anthropic documentation rather than rumors.
For practical testing, Chat4O AI is useful as a multi-model workflow platform because it gives users a place to compare Claude-style work with GPT, Gemini, Grok, DeepSeek, and other model families. However, direct Claude Opus 4.8 access on Chat4O should be verified on the live model list before claiming availability. Until a direct Opus 4.8 page is live, the relevant Chat4O path is to test Claude workflows through pages such as Claude Sonnet 4.5 on Chat4O and related Claude model content.

Quick Answer: What Was in the Claude Opus 4.8 Release?
Claude Opus 4.8 is Anthropic’s May 28, 2026 Opus update for professional reasoning, coding, and agent workflows. The official announcement frames it as an upgrade over Claude Opus 4.7 with stronger coding and long-running task performance, better collaboration behavior, and continued support for professional developer and enterprise use cases.
The most important release-watch point is that Opus 4.8 is not just a casual chat update. Anthropic’s docs position it as the strongest model for “complex agents, coding, and reasoning,” while also providing a documented API model ID: claude-opus-4-8. That matters for developers because model names, prompt caching behavior, fast mode, and API constraints affect how teams test and deploy the model.
For everyday users, the practical takeaway is simpler. Claude Opus 4.8 is worth tracking if your tasks involve difficult code review, architecture planning, research synthesis, multi-step agent design, or long documents where the model must preserve context and handle ambiguity. If you mostly need fast everyday chat, drafting, or lighter analysis, Claude Sonnet 4.5 or another model may remain the more cost-sensitive starting point.
Before publishing any fixed claim about access, check the live Anthropic and Chat4O pages. Availability, region support, rate limits, context window behavior, prompt caching rules, fast mode, and platform support can change.

Claude Opus 4.8 Features: Coding, Reasoning, Agents, and Long Context
The Claude Opus 4.8 feature story centers on higher-reliability professional work, not on a single flashy demo. Anthropic’s official material emphasizes coding improvements, better agentic performance, long-context capability, and stronger collaboration behavior. Those are exactly the areas where a model update can matter to teams that already use AI for real workflows.
For coding, the most useful test is not “can it write code?” Most frontier models can write plausible code. A better Claude Opus 4.8 coding test asks whether the model can read a messy change request, inspect assumptions, choose a safe implementation path, identify edge cases, and propose tests before editing. That is where stronger reasoning and agentic behavior are more useful than a quick autocomplete answer.
For long-context tasks, the key is whether the model stays grounded. A user might give it a product brief, support logs, source snippets, and a prior architecture decision. A stronger model should separate confirmed facts from assumptions, preserve constraints, and avoid inventing missing details. Official docs describe Opus 4.8 in the context of large context windows, but teams should still verify the exact limits and platform behavior for their chosen access route.
For agents and tools, the right benchmark is workflow reliability. Can the model plan a multi-step task, call tools only when useful, recover from partial failure, and hand work back to a human at the right review point? Claude Opus 4.8 is worth testing if your team cares about those questions more than a simple chatbot answer.

Claude Opus 4.8 vs Claude Opus 4.7: What Changed?
Claude Opus 4.8 should be understood as an incremental but important upgrade over Opus 4.7. Anthropic’s “What’s New” documentation lists model-specific updates and API behavior changes, including the claude-opus-4-8 model ID, a fast mode option, prompt caching changes, effort defaults, and inherited constraints from Opus 4.7.
The comparison should be made across use cases, not marketing labels. If Opus 4.7 already handled your daily writing, light coding, and short analysis tasks well, Opus 4.8 may not change your everyday workflow dramatically. If your work involves complex repositories, long-running agents, large document review, or professional coding tasks, then Opus 4.8 is more likely to justify a pilot test.
For API users, the docs are especially important. Anthropic describes fast mode as a capability that prioritizes speed for certain contexts, while also documenting constraints around temperature and sampling settings for Opus 4.8. The docs also mention lower minimum token requirements for prompt caching compared with earlier behavior. These details matter because the same prompt can behave differently depending on API settings, surface, and mode.
Use this comparison frame:
| Question | What to test |
|---|---|
| Is Opus 4.8 better for coding? | Run real bug reports, code review tasks, refactors, and test-generation prompts. |
| Is it better for reasoning? | Use decision memos, research synthesis, long documents, and contradiction checks. |
| Is it better for agents? | Test multi-step tool workflows with failure recovery and human review points. |
| Is it worth the cost? | Compare task success, revision time, speed, and token cost against your current model. |
| Is it ready for production? | Verify API limits, region access, security review, logging, and platform support. |
The safe conclusion is that Claude Opus 4.8 deserves a structured pilot, not blind migration.

Claude Opus 4.8 API: Model ID, Fast Mode, Prompt Caching, and Settings to Verify
Developers should treat Claude Opus 4.8 as an API configuration update as much as a model release. The official docs identify claude-opus-4-8 as the model ID and document API behavior that can affect evaluation results, including fast mode, effort defaults, prompt caching, adaptive thinking, and inherited constraints from Opus 4.7.
Before building around Claude Opus 4.8, verify these items in Anthropic’s current docs:
- Current model ID and whether aliases are available.
- Pricing and whether the release still uses the same listed Opus pricing.
- Context window and max output limits for your platform surface.
- Fast mode availability, pricing behavior, and quality trade-offs.
- Prompt caching rules and minimum token thresholds.
- Supported sampling settings, effort settings, and tool-use behavior.
- Region availability, enterprise access, data policies, and platform-specific limits.
This verification step is not busywork. It protects teams from comparing models unfairly. For example, a prompt run with prompt caching, fast mode, different output limits, or a different surface can look like a model-quality difference when it is actually a configuration difference.
The best API test is repeatable. Create a small benchmark set from your own work: code review, bug triage, research summary, spreadsheet reasoning, long document analysis, and an agent-planning task. Run the same tasks on Opus 4.8, Sonnet 4.5, your current GPT model, and any other candidate. Score not only answer quality but also correction time, hallucination risk, latency, and cost sensitivity.

How to Test Claude AI on Chat4O Without Overclaiming Opus 4.8 Access
Chat4O AI is best positioned in this article as a practical multi-model testing platform, not as confirmed direct Claude Opus 4.8 access unless a direct model page is visible on the live site. That distinction is important for trust. Readers can use Chat4O to compare Claude-style workflows and related models while tracking whether a Claude Opus 4.8 page becomes available.
Start with Claude Sonnet 4.5 on Chat4O if you want a current Claude-style reasoning and coding workflow on the platform. Chat4O also lists or references older Claude pages such as Claude 4 Sonnet and Claude 3.7 Sonnet, which can help users understand how Claude-family workflows feel across versions. For broader comparison, Chat4O’s platform positioning supports testing across GPT, Gemini, Grok, DeepSeek, and other AI models.
Use Chat4O for workflow comparison rather than final benchmark claims. A good platform test asks questions like:
- Which model follows my coding instructions with the least correction?
- Which model handles long context without losing key constraints?
- Which model is fastest for everyday drafting?
- Which model gives the clearest research uncertainty notes?
- Which model works best for agent planning and tool workflows?
When writing about Claude AI on Chat4O, use careful language: “try Claude-style workflows,” “test available Claude models,” or “track future Claude Opus availability.” Avoid saying “use Claude Opus 4.8 on Chat4O” unless a direct page is live and verified.

Claude Opus 4.8 vs GPT, Gemini, Grok, and Other Frontier Models
Claude Opus 4.8 vs GPT comparisons should be based on workflow fit, not a universal “best model” claim. Developers, analysts, writers, researchers, and automation builders often need different strengths, so a model that wins one task may not be the best choice for another.
Use Claude Opus 4.8 when the task rewards careful reasoning, complex coding, long-context analysis, or agent planning. Use GPT models when your existing workflow, tool ecosystem, or product integration already depends on them and they perform well in your internal tests. Use Gemini when Google ecosystem access, multimodal workflows, or workspace integration matters. Use Grok when your use case benefits from that model’s product surface or real-time-style workflows. Use DeepSeek or other models when cost, open-weight behavior, or specific technical constraints matter.
The strongest comparison method is a rubric:
| Criterion | Why it matters |
|---|---|
| Reasoning quality | Can the model separate facts, assumptions, and uncertainty? |
| Coding reliability | Does it produce safe plans, useful patches, and relevant tests? |
| Long-context behavior | Does it retain constraints across large documents or codebases? |
| Speed | Is latency acceptable for the user workflow? |
| Cost sensitivity | Does the quality improvement justify the spend? |
| Agent reliability | Can it plan, use tools, recover from errors, and ask for review? |
| Platform fit | Is it available where your team actually works? |
This is where Chat4O is useful: it gives teams a practical place to compare available model workflows before they commit to a specific API, subscription, or production process.

Prompt Formula and Copy-to-Use Claude Opus 4.8 Test Prompts
The best Claude Opus 4.8 prompt tests should reflect real work, not artificial riddles. A good prompt gives the model a clear task type, background, role, output format, reasoning depth, and constraints. That lets you judge whether the model can be useful in your workflow.
Use this reusable prompt formula:
Use Claude Opus 4.8-style reasoning for [task type]. Goal: [specific outcome]. Context: [background, files, codebase, data, constraints]. Role: act as [developer/research analyst/editor/strategist/agent planner]. Output format: [step-by-step plan, code patch, table, report, checklist, decision memo]. Reasoning depth: [quick / standard / deep]. Constraints: verify assumptions, flag uncertainty, ask only essential questions, avoid unsupported claims, and provide testable next steps.
Copy and adapt these prompts:
- Review this codebase change request as a senior engineer. Identify the safest implementation path, likely edge cases, files to inspect, tests to add, and risks before writing code. Output a step-by-step engineering plan.
- Analyze this bug report and propose a debugging strategy. Separate confirmed facts from assumptions, list likely root causes, suggest logs or tests to run, and recommend the smallest safe fix.
- Refactor this function for readability and maintainability. Preserve behavior, explain the changes, add comments only where useful, and include test cases for edge conditions.
- Compare Claude Opus 4.8, Claude Sonnet 4.5, GPT-5.5, and Gemini for my workflow. My use case is [describe use case]. Rank them by reasoning, coding, cost sensitivity, speed, and long-context reliability.
- Turn this rough research question into a structured research plan. Include subquestions, search terms, source types, verification steps, possible biases, and an outline for the final report.
- Review this long document and extract the key claims, weak evidence, contradictions, missing citations, and recommended revisions. Keep the output concise but specific.
- Act as an AI agent architect. Design a multi-step workflow for [task], including trigger, tools, memory needs, safety checks, failure modes, and human review points.
- Create a decision memo for whether our team should test Claude Opus 4.8. Include potential benefits, risks, cost considerations, security concerns, benchmark caveats, and pilot-test criteria.
- Write a prompt-testing plan for comparing Claude Opus 4.8 with our current model. Include 10 representative tasks, scoring criteria, failure cases, and review rubric.
- Rewrite this technical explanation for executives. Preserve accuracy, remove jargon, highlight business impact, and include a short risk section.
Run these prompts across models only after removing private data. For team use, keep a review rubric so every model is scored against the same criteria.

FAQ and Final Recommendation
Was Claude Opus 4.8 officially released?
Yes. Anthropic officially announced Claude Opus 4.8 on May 28, 2026. Use Anthropic’s announcement and platform docs as the primary sources for release details, model ID, API behavior, and current constraints.
What is the Claude Opus 4.8 API model ID?
Anthropic’s documentation identifies the model ID as claude-opus-4-8. Developers should verify the current model overview and “What’s New” docs before deployment because aliases, platform support, pricing, and settings can change.
Is Claude Opus 4.8 better than Claude Opus 4.7?
Anthropic presents Opus 4.8 as an upgrade over Opus 4.7, especially for coding, reasoning, collaboration, and professional workflows. The best answer for your team depends on pilot tests using your own code, documents, data, and agent tasks.
Can I use Claude Opus 4.8 on Chat4O AI?
Do not assume direct Opus 4.8 access on Chat4O unless a live Claude Opus 4.8 model page or model-list entry is verified. Chat4O is still useful for testing available Claude-style workflows, including Claude Sonnet 4.5, and comparing Claude with GPT, Gemini, Grok, and other models.
What should developers test first?
Start with code review, bug triage, refactoring, architecture planning, and agent-workflow design. These tasks reveal whether Claude Opus 4.8 improves not just answer fluency, but planning quality, uncertainty handling, test suggestions, and safe implementation choices.
Conclusion
The Claude Opus 4.8 Release is important because it pushes Claude further into professional coding, reasoning, agentic work, and long-context workflows. The right next step is not to accept broad “best model” claims, but to run a careful pilot: verify Anthropic’s current docs, test representative prompts, compare available Claude AI on Chat4O with GPT, Gemini, Grok, and other models, and decide based on reliability, cost, speed, and workflow fit.